Среди них — выполнение мелких задач и постоянный контроль со стороны руководства.
Ощущение, что нас недооценивают, часто становится причиной дискомфорта на работе. Но прежде чем разбираться, откуда оно возникает и как с ним справиться, важно определить, какой смысл вы вкладываете в понятие «ценность». Для одних это продвижение по карьерной лестнице, а для других — хорошие отношения с боссом.
Как понять, что вас недооценивают
Опасные сигналы могут быть самыми разными. И далеко не все из них очевидны с первого взгляда. Человек должен обладать высоким эмоциональным интеллектом и острым чутьём, чтобы распознать ранние признаки того, что его недооценивают, потому что они довольно незначительны. Вот некоторые из них.
1. Ваше мнение игнорируют
Когда коллеги или босс регулярно пренебрегают вашими предложениями или выдают их за свои, они посылают вам сообщение: «Ты не предлагаешь ничего стоящего».
Если такое часто происходит с вами, сначала убедитесь, что чётко и доходчиво доносите свои мысли. Если проблема не в этом, напрямую спросите, почему ваши предложения не учитываются. Например: «Пожалуйста, помогите мне разобраться, что не так с моей идеей». Такая формулировка не будет звучать как атака, а значит, у собеседника не возникнет желания защищаться.
2. Вы не вникаете в работу
Отстранённость — частый симптом того, что вас не ценят. Все мы хотим чувствовать связь с окружающими, ощущать свою значимость и знать, что нас слышат. Это наша нейропсихологическая потребность. Когда она не удовлетворяется, мы перестаём вникать в то, чем занимаемся.
Поэтому, если вы часто «отключаетесь» от рабочих задач, возможно, всё дело во внутреннем ощущении того, что вас не ценят.
3. Вам поручают только мелкие задачи
Когда вы день за днём заняты незначительными задачами, которые не относятся к вашим обязанностям и не задействуют ваши профессиональные навыки, — например, готовите кофе или делаете заметки на совещании, — это тревожный сигнал. Компаниям нужны люди, которые будут выполнять мелкие поручения, но это не значит, что все скучные рутинные дела должны ложиться на вас. Особенно если коллегам в это время поручают более интересные перспективные проекты.
Прежде чем вы в очередной раз согласитесь вести записи на собрании, определите свои приоритеты. Каждое ваше «да» одной задаче означает неявное «нет» другой. Если долго заниматься делами на несколько уровней ниже ваших способностей, однажды наступит момент, когда работа перестанет вас радовать.
Проанализируйте, что главные люди в вашей компании считают важным, какие цели ставят перед собой и как вы можете помочь их достичь. Как только вы найдёте ответы, поговорите с руководителем. Скажите, что вы заметили свободную нишу, и спросите, занимается ли этим направлением кто-то из сотрудников и не требуется ли ваша помощь.
Если вы уже объясняли начальству, что хотите развиваться, но ничего не меняется, возможно, причина в другом. Видимо, ваше руководство по какой-то причине не считает вас сильным игроком. Побороть это предубеждение может быть сложно. Подумайте, хочется ли вам тратить на это время.
4. Вашу работу контролируют
Когда руководитель занимается микроменеджментом, значит, он не настолько высоко вас ценит, чтобы предоставить вам полную независимость.
Если босс постоянно мониторит вашу деятельность, а не просто даёт вам задачи, попробуйте предложить ему эксперимент. Например: «Я знаю, что вы переживаете по поводу дедлайна. Но когда вы постоянно проверяете, как идут дела, я теряю внимание, а это мешает сделать всё вовремя. Давайте я попробую работать самостоятельно». Не забудьте упомянуть, что это именно эксперимент. Так будет больше шансов, что начальник согласится.
5. У вас маленькая зарплата
Ваша зарплата — один из главных индикаторов того, насколько компания ценит ваш вклад. Если вам дают хорошую обратную связь и постоянно хвалят, но не поднимают зарплату — вас явно недооценивают.
Это может казаться несерьёзной проблемой сейчас. Однако со временем вероятность того, что вы продолжите получать меньше, чем заслуживаете, увеличивается. Ваша нынешняя зарплата служит стартовой точкой для будущих переговоров. Гораздо легче договориться о зарплате в 65 тысяч, если вы уже получаете 60, а не 50.
Если вы подозреваете, что мало получаете, изучите рынок и узнайте, сколько зарабатывают специалисты вашего уровня. С этой информацией можно идти к боссу и построить разговор, например, следующим образом: «Обязанности, которые я выполняю, не соответствуют моей должности и зарплате. Что нужно, чтобы мы обсудили и пересмотрели моё положение в компании?»
Как исправить ситуацию
Если вам знаком любой из пяти сигналов, значит, пора поговорить с руководителем. Не стоит молча принимать тот факт, что ваш потенциал зарывают в землю. Но вместо того чтобы жаловаться, начните действовать. Помните, что именно вы управляете своей карьерой. Заступайтесь за себя, хотя бы ради своего ментального здоровья.
Если это не сильно вас мотивирует, посчитайте, сколько денег вы теряете, оставаясь на работе, где вас не ценят. Подумайте, действительно ли вы предпочитаете избегать неудобного разговора и продолжать зарабатывать меньше. Не защищать свои интересы обходится слишком дорого.
Тренды трендами, а всегда найдутся те, кто плывет против течения. Пока трендом становится уменьшение размеров модели, авторы из университета штата Вашингтон решили вообще не обращать внимание на размер и проверить, имеет ли смысл в эпоху LLM вернуться к N-граммным языковым моделям. Оказалось, что имеет. Во всяком случае, хотя бы просто из интереса.
На N-граммы, пожалуй, действительно давно никто не обращал внимания. Техники масштабирования, выведшие трансформеры на заоблачные высоты, к ним не применяли. Но авторы статьи Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens обучили N-граммную модель на 1,4 триллиона токенов — это самая гигантская модель такой архитектуры. Она занимает 10 тебибайт, зато ей нужно всего 20 миллисекунд, чтобы подсчитать n-граммы, вне зависимости от того чему равно n. Самое интересное — возможные значения n.
Развитие n-граммных моделей быстро уперлось в экспоненциальный рост размера от n. Уже при 5-граммах на адекватном датасете число комбинаций, для которых нужно сохранить значения в таблицу вероятностей, очень большое, поэтому дальше 5 не заходили. Но и 5 (а на самом деле 4) токенов — настолько маленький контекст, что даже о сравнении с LLM речи не шло. Но авторы статьи не просто подняли n выше 5, они сняли любые ограничения — n может быть сколь угодно большим. Поэтому авторы условно называют это ∞-граммы, или “бесконечнограммы”. Конечно, для этого пришлось немного модифицировать подход.
Числитель и знаменатель в дроби, которая определяет вероятность токена после заданного контекста, могут оказаться нулевыми. Имеется в виду простое определение, когда просто подсчитывается количество заданных n-грамм в корпусе. То есть, если таких последовательностей токенов в корпусе не было, то и посчитать ничего не получится. Чтобы справится с этим, да еще и на бесконечнограммах, авторы применили backoff-технику, то есть технику откидывания. Если числитель и знаменатель равны нулю, будем уменьшать n на единицу до тех пор, пока знаменатель не станет положительным (числитель может остаться нулем). Отбрасывание начинается условно с бесконечности. На деле начальное “бесконечное” n рассчитывается как длина самого длинного суффикса из промпта, который встречается в корпусе, плюс один.
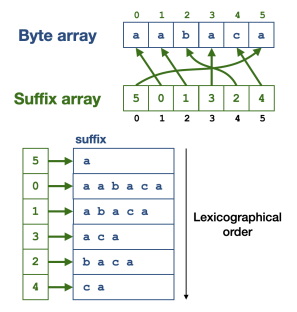
10 тебибайт, конечно, очень даже небольшой размер для бесконечнограммной модели на 1,4 миллиарде токенов (классическая 5-граммная модель весила бы 28 тебибайт). Чтобы добиться этого, авторы составили специальную структуру данных — массив суффиксов. Следите за руками. Для заданного массива длиной N сначала строятся все возможные суффиксы и выстраиваются в лексикографическом порядке. Массив суффиксов построен таким образом, что на нулевом месте стоит позиция, на котором в исходном массиве впервые встречается нулевой суффикс. На первом — позиция, где встречается первый и так далее.
Массив суффиксов строится за линейное время относительно длины токенизированного корпуса. На RedPajama c 1,4 триллиона токенов на это ушло 56 часов, 80 CPU и 512G RAM.
Чтобы посчитать вероятность n-граммы, нужно посчитать число “иголок” (строчек из токенов заданной длины) в “стоге сена” (массиве суффиксов). А так как этот стог отражает упорядоченный набор всех суффиксов, то позиции всех нужных “иголок” находятся в одном последовательном фрагменте массива суффиксов. Поэтому нужно просто найти первый и последний и посчитать разницу ними. Это занимает логарифмическое по размеру массива и линейное по размеру искомой строки время.
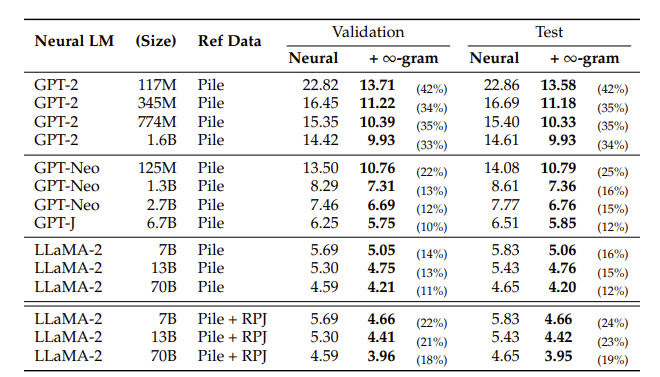
Авторы прикрутили бексконечнограмы к большим языковым моделям с помощью линейной интерполяции и оценили перплексию на датасете Pile. На GPT-2, GPT-Neo и LLaMa-2 улучшения оказались весьма убедительными — от 12% до 42% на тестовой выборке. Авторы, правда добавляют, что такое заметное улучшение GPT-2 может быть из-за того, что её единственную не обучали на Pile
Еще одно важное замечание авторов. Бесконечнограммы могут значительно улучшать перплексию LLM, но на задачах генерации открытого текста могут не просто не помогать, а еще и мешать. Бесконечнограмы могут, например, извлекать совершенно не нужные токены и модель выдаст ерунду. Так что на замену LLM авторы совсем не претендуют. Но всё равно планируют поискать тут возможные способы совместного применения.
События – это объекты, которые получают уведомления о некотором действии в разрабатываемом ПО и могут запускать реакции на это действие. Разработчик может определить эти действия, добавив к событию обработчик. Разберем в этом материале само понятие событий в .NET и разные способы работы с ними.
Объясним на сахаре
Если говорить простым языком, то можно провести аналогию с просыпанным сахаром. Например, у нас в руках была сахарница, и мы сахар из нее рассыпали – это событие. Что делать, если рассыпался сахар? Идти за веником, чтобы убрать – это и есть обработчик события. Этот обработчик с предназначенным для него действием «сидит у нас в голове». Даже если сахар мы никогда не просыпали, мы все равно знаем, что веником его можно будет убрать.
Обработчик может меняться. Например, мы покупаем пылесос – теперь у нас в голове меняется обработчик для того же события: мы пойдем не за веником, а за пылесосом (один обработчик мы удалили, другой добавили). Изменение обработчика не влияет на событие. Обработчика может и не быть вовсе – тогда человек будет просто ходить по просыпанному сахару.
О событиях в C#
В C# события существуют с самого начала. Например, при создании элементарного приложения Web Forms, для обработки нажатия на кнопку нужно добавить конструкцию вида
MyButton.Click += new EventHandler(this.MyBtn_Click);
Сlick – это и есть событие, которое уже было добавлено разработчиками в класс Button, а MyBtn_Click – это обработчик, написанный программистом.
Сейчас события используются реже, но возможность создавать и использовать их сохранилась. Так как же это устроено изнутри?
Первое, что хочется отметить: такой физической сущности как событие нет. Потому что событие будет являться делегатом, ссылкой на метод, который мы можем определить, а можем и не определить в дальнейшем. То есть по сути существует лишь обработчик события, и это вызывает некоторую путаницу в формулировках.
Основная суть добавления событий – внести возможность различной обработки события для объекта в разных частях программы, а также – возможность добавить обработчик к объекту. Потом можно изменить, добавить новый или убрать текущий обработчик в другом месте при работе с тем же объектом.
В C# события – это отдельный тип членов класса, обозначаемый ключевым словом event. Наряду со свойствами и параметрами.
Класс, который реализует событие, должен содержать следующую конструкцию:
event тип_делегата имя_события;
тип_делегата указывает на прототип вызываемого метода (или методов);
имя_события – конкретный объект объявляемого события.
Добавление обработчика события производится с помощью операции += :
имя_события += обработчик_события;
Разберем добавление обработки событий на примере логирования. Здесь, и в дальнейшем, мы будем использовать консольное приложение .Net 7.0, C# 11.
class Program
{
static void Main()
{
EmailService emailService = new EmailService(emailFrom: "hr@disney.com");
// Добавляем обработчик события
emailService.MailSent += LogToConsole;
emailService.SendMail(emailTo: "Milo.Murphy@disney.com", subject: "Welcome to Disney", body: "Today is your first day...");
}
// Обработчик, который логирует в консоль отправленное сообщение
static void LogToConsole(MailSentEventArgs eventArgs)
=> Console.WriteLine(
$"[Консоль] Письмо с темой '{eventArgs.Subject}' отправлено с адреса '{eventArgs.EmailFrom}' на адрес '{eventArgs.EmailTo}': {eventArgs.Body}");
}
// Класс в котором реализовано событие
class EmailService
{
private readonly string _emailFrom;
public EmailService(string emailFrom)
{
_emailFrom = emailFrom;
}
// Объявляем событие
public event MailSentEventHandler? MailSent;
public void SendMail(string emailTo, string subject, string body)
{
// Отправляем письмо пользователю...
// Send(_emailFrom, emailTo, subject, body);
// Вызываем метод запуска события
var eventArgs = new MailSentEventArgs
{
EmailFrom = _emailFrom,
EmailTo = emailTo,
Subject = subject,
Body = body
};
OnMailSent(eventArgs);
}
// Используем метод для запуска события
protected virtual void OnMailSent(MailSentEventArgs eventArgs)
{
MailSentEventHandler? mailSentHandler = MailSent;
if (mailSentHandler != null)
{
mailSentHandler(eventArgs);
}
}
}
// Объявляем тип события
public delegate void MailSentEventHandler(MailSentEventArgs eventArgs);
public record MailSentEventArgs
{
public string? EmailFrom { get; init; }
public string? EmailTo { get; init; }
public string? Subject { get; init; }
public string? Body { get; init; }
}
Мы добавили событие MailSent в класс EmailService и добавили обработчик этого события LogToConsole.
Результат:
[Консоль] Письмо с темой 'Welcome to Disney' отправлено с адреса 'hr@disney.com' на адрес 'Milo.Murphy@disney.com': Today is your first day...
Добавление и удаление обработчиков
Можно добавить несколько обработчиков, они будут выполняться последовательно. Несколько обработчиков могут понадобиться, например, чтобы записывать одни и те же логи в разные места.
Цепочка обработчиков реализуется через Delegate.Combine. То есть физически каждый делегат содержит ссылку на реализацию, внутри которой ссылка на следующую реализацию. Обработчик можно удалить в процессе.
static void Main()
{
EmailService emailService = new EmailService(emailFrom: "hr@disney.com");
// Добавляем обработчик события
emailService.MailSent += LogToConsole;
emailService.MailSent += LogToFile;
emailService.SendMail(emailTo: "Milo.Murphy@disney.com", subject: "Welcome to Disney", body: "Today is your first day...");
emailService.MailSent -= LogToFile;
emailService.SendMail(emailTo: "Milo.Murphy@disney.com", subject: "Welcome to Disney", body: "Today is your first day...");
}
// Обработчик, который логирует в консоль отправленное сообщение
static void LogToConsole(MailSentEventArgs eventArgs)
=> Console.WriteLine(
$"[Консоль] Письмо с темой '{eventArgs.Subject}' отправлено с адреса '{eventArgs.EmailFrom}' на адрес '{eventArgs.EmailTo}': {eventArgs.Body}");
// Обработчик, который логирует в файл отправленное сообщение
static void LogToFile(MailSentEventArgs eventArgs)
=> Console.WriteLine(
$"[Файл] Письмо с темой '{eventArgs.Subject}' отправлено с адреса '{eventArgs.EmailFrom}' на адрес '{eventArgs.EmailTo}': {eventArgs.Body}");
Результат:
[Консоль] Письмо с темой 'Welcome to Disney' отправлено с адреса 'hr@disney.com' на адрес 'Milo.Murphy@disney.com': Today is your first day...
[Файл] Письмо с темой 'Welcome to Disney' отправлено с адреса 'hr@disney.com' на адрес 'Milo.Murphy@disney.com': Today is your first day...
[Консоль] Письмо с темой 'Welcome to Disney' отправлено с адреса 'hr@disney.com' на адрес 'Milo.Murphy@disney.com': Today is your first day...
Если нужно выполнить какие-то действия при добавлении или удалении обработчика, можно переписать функции add/remove у делегата. Мы добавим логирование к действиям добавления/удаления обработчика.
Обработчик LogToConsole добавлен
Обработчик LogToFile добавлен
[Консоль] Письмо с темой 'Welcome to Disney' отправлено с адреса 'hr@disney.com' на адрес 'Milo.Murphy@disney.com': Today is your first day...
[Файл] Письмо с темой 'Welcome to Disney' отправлено с адреса 'hr@disney.com' на адрес 'Milo.Murphy@disney.com': Today is your first day...
Обработчик LogToFile удален
[Консоль] Письмо с темой 'Welcome to Disney' отправлено с адреса 'hr@disney.com' на адрес 'Milo.Murphy@disney.com': Today is your first day..
Если в обработчике произойдет ошибка – ошибка будет на уровне приложения. Если добавить try catch при вызове обработчика, то в случае, если произойдет ошибка в первом обработчике, последующие обработчики выполняться не будут. Поэтому следует предусмотреть это в каждом обработчике.
В .NET существует делегат EventHandler, предназначенный как раз для объявления события и принимающий определенный тип входных параметров.
Классы, которые мы собираемся использовать для хранения информации, передаваемой обработчику события, должны наследоваться от типа System.EventArgs. При этом имя типа желательно заканчивать словом EventArgs.
Создадим тип параметров, используемых обработчиками:
public class MailSentEventArgs : EventArgs
{
public string? EmailFrom { get; init; }
public string? EmailTo { get; init; }
public string? Subject { get; init; }
public string? Body { get; init; }
}
И тогда событие может быть объявлено как
public event EventHandler<MailSentEventArgs>? MailSent;
При этом обработчик должен принимать параметры object sender и MailSentEventArgs args. Где sender – текущий элемент класса, в котором определен event, a args – передаваемые обработчику данные. Обработчик может быть использован для событий в разных классах, поэтому разумнее принимать экземпляр типа object, а не конкретного типа. Так как в этом случае в метод обработчика могут приходить данные от разных событий, но с одинаковыми параметрами.
То есть обработчики будут выглядеть так:
public static void LogToConsole(object? sender, MailSentEventArgs args)
=> Console.WriteLine(
$"[Консоль] Письмо с темой '{args.Subject}' отправлено с адреса '{args.EmailFrom}' на адрес '{args.EmailTo}': {args.Body}");
public static void LogToFile(object? sender, MailSentEventArgs args)
=> Console.WriteLine(
$"[Файл] Письмо с темой '{args.Subject}' отправлено с адреса '{args.EmailFrom}' на адрес '{args.EmailTo}': {args.Body}")
А вызов, поскольку событие представляет собой делегат, например, так:
MailSent?.Invoke(this, eventArgs);
Порой необходимо передать внутрь функции какие-то данные, а порой действие будет выполняться независимо от внешних данных – тогда передавать внутрь функции ничего не нужно. В случаях, когда не нужно передавать в обработчик никаких данных, мы можем воспользоваться EventArgs.Empty. То есть объявление события не будет указывать тип аргумента:
public event EventHandler? MailSent;
Обработчик при этом должен принимать object sender и EventArgs:
Обработка делегатов может быть асинхронной. С ее помощью получается лучше распределить ресурсы компьютера и потоки обработки данных – это полезно в случаях, когда операция находится в режиме ожидания достаточно длительное время и мы выигрываем в скорости от перераспределения потоков.
Подключив к проекту Microsoft.VisualStudio.Threading, получаем возможность сделать обработку делегатов асинхронной.
Тогда объявлять событие мы будем так:
public event AsyncEventHandler<MailSentEventArgs>? MailSent;
Обработчик будет выглядеть так:
static Task LogToConsoleAsync(object? sender, MailSentEventArgs args)
{
Console.WriteLine(
$"[Консоль] Письмо с темой '{args.Subject}' отправлено с адреса '{args.EmailFrom}' на адрес '{args.EmailTo}': {args.Body}");
return Task.CompletedTask;
}
а вызываться так:
await MailSent?.InvokeAsync(this, new MailSentEventArgs());
Реализация событий компилятором
Несколько слов о представлении событий в IL-кодe. При компиляции кроме объявления события также создаются два метода add и remove: они реализуют конструкции += и –=.
Для наглядности можно скомпилировать и декомпилировать обратно наш код. Тогда станет видно, что добавляет компилятор. Прогнав таким образом наш первоначальный код здесь мы получим следующий код в месте создания события.
public event MailSentEventHandler MailSent
{
[NullableContext(2)]
[CompilerGenerated]
add
{
MailSentEventHandler mailSentEventHandler = this.MailSent;
while (true)
{
// берем текущий делегат
MailSentEventHandler mailSentEventHandler2 = mailSentEventHandler;
// добавляем к текущему делегату новый
MailSentEventHandler value2 = (MailSentEventHandler)Delegate
.Combine(mailSentEventHandler2, value);
// сравниваем MailSent и mailSentEventHandler2
// и, если они равны, заменяем MailSent на value2
// а в mailSentEventHandler записываем исходное значение MailSent
mailSentEventHandler = Interlocked
.CompareExchange(ref this.MailSent, value2, mailSentEventHandler2);
// если предыдущая операция выполнилась успешно - заканчиваем
// это нужно для безопасной многопоточной работы - если в
// параллельном потоке у события изменится список делегатов,
// то while запустится повторно и добавит новый делегат к уже
// обновленной цепочке делегатов
if ((object)mailSentEventHandler == mailSentEventHandler2)
{
break;
}
}
}
[NullableContext(2)]
[CompilerGenerated]
remove
{
MailSentEventHandler mailSentEventHandler = this.MailSent;
while (true)
{
// берем текущий делегат
MailSentEventHandler mailSentEventHandler2 = mailSentEventHandler;
// удаляем из него value
MailSentEventHandler value2 = (MailSentEventHandler)Delegate
.Remove(mailSentEventHandler2, value);
// сравниваем MailSent и mailSentEventHandler2
// и, если они равны, заменяем MailSent на value2
// а в mailSentEventHandler записываем исходное значение MailSent
mailSentEventHandler = Interlocked
.CompareExchange(ref this.MailSent, value2, mailSentEventHandler2);
// если предыдущая операция выполнилась успешно - заканчиваем
if ((object)mailSentEventHandler == mailSentEventHandler2)
{
break;
}
}
}
}
Паттерн «Наблюдатель»
Реализация событий укладывается в паттерн «Наблюдатель», суть которого в наличии одного наблюдаемого объекта и нескольких наблюдателей. Если возвращаться к аналогии с сахаром, в рамках паттерна сахарница будет наблюдаемым объектом, а человек, который рассыпал сахар или просто находился рядом – наблюдателем. Наблюдателей может быть больше одного (кто-то с веником, а кто-то с пылесосом). Далее, когда рассыпается сахар, сначала один наблюдатель делает свои действия, а другой следом – свои.
Паттерн «Наблюдатель» можно реализовать через добавления наблюдателей как реализаций делегата, а можно – через добавление наблюдателей в список, хранящийся в наблюдаемом объекте.
Ниже приведен пример реализации этого паттерна без использования событий.
class Program
{
static void Main()
{
EmailService emailService = new EmailService("hr@disney.com");
// Добавляем обработчик события
var consoleObserver = new ConsoleObserver(emailService);
var fileObserver = new FileObserver(emailService);
emailService.SendMail(
emailTo: "Milo.Murphy@disney.com",
subject: "Welcome to Disney",
body: "Today is your first day...");
fileObserver.StopObserve();
emailService.SendMail(
emailTo: "Milo.Murphy@disney.com",
subject: "Welcome to Disney",
body: "Today is your first day...");
}
}
interface IObserver
{
void Update(string emailFrom, string emailTo, string subject, string body);
}
interface IObservable
{
void RegisterObserver(IObserver o);
void RemoveObserver(IObserver o);
}
class EmailService : IObservable
{
private readonly List<IObserver> _observers;
private readonly string _emailFrom;
public EmailService(string emailFrom)
{
_emailFrom = emailFrom;
_observers = new List<IObserver>();
}
public void RegisterObserver(IObserver o)
{
_observers.Add(o);
}
public void RemoveObserver(IObserver o)
{
_observers.Remove(o);
}
protected void MailSent(string emailTo, string subject, string body)
{
foreach (IObserver o in _observers)
{
o.Update(_emailFrom, emailTo, subject, body);
}
}
public void SendMail(string emailTo, string subject, string body)
{
// Отправить письмо пользователю
//Send(_emailFrom, emailTo, subject, body);
// Запускаем методы наблюдателей
MailSent(emailTo, subject, body);
}
}
class ConsoleObserver : IObserver
{
IObservable? _stock;
public ConsoleObserver(IObservable obs)
{
_stock = obs;
_stock.RegisterObserver(this);
}
public void Update(
string emailFrom,
string emailTo,
string subject,
string body)
{
Console.WriteLine($"[Консоль] Письмо с темой '{subject}' отправлено с адреса '{emailFrom}' на адрес '{emailTo}': {body}");
}
public void StopObserve()
{
if (_stock is null)
{
return;
}
_stock.RemoveObserver(this);
_stock = null;
}
}
class FileObserver : IObserver
{
IObservable? _stock;
public FileObserver(IObservable obs)
{
_stock = obs;
_stock.RegisterObserver(this);
}
public void Update(
string emailFrom,
string emailTo,
string subject,
string body)
{
Console.WriteLine($"[Файл] Письмо с темой '{subject}' отправлено с адреса '{emailFrom}' на адрес '{emailTo}': {body}");
}
public void StopObserve()
{
if (_stock is null)
{
return;
}
_stock.RemoveObserver(this);
_stock = null;
}
}
Результат:
[Консоль] Письмо с темой 'Welcome to Disney' отправлено с адреса 'hr@disney.com' на адрес 'Milo.Murphy@disney.com': Today is your first day...
[Файл] Письмо с темой 'Welcome to Disney' отправлено с адреса 'hr@disney.com' на адрес 'Milo.Murphy@disney.com': Today is your first day...
[Консоль] Письмо с темой 'Welcome to Disney' отправлено с адреса 'hr@disney.com' на адрес 'Milo.Murphy@disney.com': Today is your first day...
Минусы и плюсы такой реализации паттерна «Наблюдатель»
Минусы
в этой реализации нам пришлось самим писать интерфейсы, а для событий есть прописанные интерфейсы и классы, которыми остается только воспользоваться;
более высокий порог вхождения – нужно разобраться с работой паттерна;
под каждое событие придется писать свой набор интерфейсов из-за различий данных события, передаваемых в метод IObserver.Update (либо аналогично событиям использовать тип object, но тогда теряется наглядность);
при этом код стал более отлаживаемым – весь код доступен для редактирования, и более прозрачным – можно пройтись по реализации и в точности посмотреть работу (в событиях, например, не очевидно, что будет, если случится эксепшен в одном из цепочки делегатов).
Плюсы
подобную реализацию можно использовать также в языках, где нет делегатов – например, С++;
можно обеспечить распараллеливание реакции наблюдателей;
можно отловить случившийся эксепшн в цепочке и обработать в зависимости от логики задачи;
точные контракты: есть конкретные методы с конкретным набором параметров под нужное событие, а не набор параметров вида «object sender, EventArgs e».
MediatR
В библиотеке MediatR из коробки есть своя реализация событий. Это не существующие в C# события, но есть некоторое сходство.
Как следует из названия, MediatR – это реализация паттерна «Посредник». Суть паттерна в создании прослойки между частями кода. Это нужно в случае наличия большого количества связей между объектами – есть вероятность запутать логику реализации.
«Посредник» ограничивает объекты от явных ссылок друг на друга, уменьшая количество взаимосвязей. Основной принцип реализации в том, что мы создаем объект и можем добавить обработчики для него. При этом достаточно использовать у типа отправляемого объекта интерфейс IRequest или INotification и указать у обработчика интерфейс, связанный с типом объекта. Тогда MediatR вызовет нужный обработчик при выполнении команды Send для интерфейса IRequest и Publish для интерфейса INotification, в который будет передан объект.
Обычно при работе с библиотекой MediatR используются интерфейсы IRequest и IRequestHandler. Тип, используемый медиатором, должен быть унаследован от IRequest<TResponse>, где TResponse – результат обработки запроса, а обработчик должен поддерживать интерфейс IRequestHandler<TRequest, TResponse>, где TRequest – созданный нами тип с интерфейсом IRequest. Но нужно помнить, что обработчик здесь может быть только один.
Для случая множества обработчиков в MediatR был создан интерфейс INotification. И, соответственно, обработчики должны поддерживать интерфейс INotificationHandler<TRequest>.
using System.Reflection;
using MediatR;
using Microsoft.Extensions.DependencyInjection;
class Program
{
static async Task Main()
{
var serviceCollection = new ServiceCollection()
.AddMediatR(cfg =>
cfg.RegisterServicesFromAssembly(Assembly.GetExecutingAssembly()))
.BuildServiceProvider();
var mediator = serviceCollection.GetRequiredService<IMediator>();
EmailService emailService = new EmailService(mediator, "hr@disney.com");
await emailService.SendMailToUserAsync(
emailTo: "Milo.Murphy@disney.com",
subject: "Welcome to Disney",
body: "Today is your first day...");
}
}
class MailSentRequest : INotification
{
public string? EmailFrom { get; init; }
public string? EmailTo { get; init; }
public string? Subject { get; init; }
public string? Body { get; init; }
}
class ConsoleHandler : INotificationHandler<MailSentRequest>
{
public Task Handle(
MailSentRequest request,
CancellationToken cancellationToken)
{
Console.WriteLine(
$"[Консоль] Письмо с темой '{request.Subject}' отправлено с адреса '{request.EmailFrom}' на адрес '{request.EmailTo}': {request.Body}");
return Task.CompletedTask;
}
}
class FileHandler : INotificationHandler<MailSentRequest>
{
public Task Handle(
MailSentRequest request,
CancellationToken cancellationToken)
{
Console.WriteLine(
$"[Файл] Письмо с темой '{request.Subject}' отправлено с адреса '{request.EmailFrom}' на адрес '{request.EmailTo}': {request.Body}");
return Task.CompletedTask;
}
}
class EmailService
{
private readonly string _emailFrom;
private readonly IMediator _mediator;
public EmailService(IMediator mediator, string emailFrom)
{
_mediator = mediator;
_emailFrom = emailFrom;
}
public async Task SendMailToUserAsync(
string emailTo,
string subject,
string body)
{
// Отправить письмо пользователю
//Send(_emailFrom, emailTo, subject, body);
// Вызываем метод запуска события
await MailSentAsync(_emailFrom, emailTo, subject, body);
}
protected async Task MailSentAsync(string emailFrom, string emailTo, string subject, string body)
{
var request = new MailSentRequest
{
EmailFrom = emailFrom,
EmailTo = emailTo,
Subject = subject,
Body = body
};
await _mediator.Publish(request);
}
}
Результат:
[Консоль] Письмо с темой 'Welcome to Disney' отправлено с адреса 'hr@disney.com' на адрес 'Milo.Murphy@disney.com': Today is your first day...
[Файл] Письмо с темой 'Welcome to Disney' отправлено с адреса 'hr@disney.com' на адрес 'Milo.Murphy@disney.com': Today is your first day...
Плюсы и минусы использования MediatR:
Плюс
использование MediatR уменьшает количество зависимостей, что будет плюсом при большом количестве объектов и связей между ними.
Минусы
классы хэндлеров помечаются не используемыми (это можно исправить, навесив атрибут [UsedImplicitly]);
нельзя «по щелчку» перейти к реализации;
не всегда очевидно, какие хэндлеры будут вызваны при вызове медиатора;
не получится во время выполнения программы добавить/удалить обработчик;
невозможно (или сложно) установить четкий порядок вызова обработчика. Он больше подходит для вызова независимых друг от друга обработчиков.
Есть способ обойти второй минус из перечисленных. Нужно реализацию запроса и обработчик поместить в один partial-класс:
public partial class MailSent
{
public class Request : INotification
{
public string? EmailFrom { get; init; }
public string? EmailTo { get; init; }
public string? Subject { get; init; }
public string? Body { get; init; }
}
}
public partial class MailSent
{
public class ConsoleHandler : INotificationHandler<Request>
{
public Task Handle(
Request request,
CancellationToken cancellationToken)
{
Console.WriteLine(
$"[Консоль] Письмо с темой '{request.Subject}' отправлено с адреса '{request.EmailFrom}' на адрес '{request.EmailTo}': {request.Body}");
return Task.CompletedTask;
}
}
}
public partial class MailSent
{
public class FileHandler : INotificationHandler<Request>
{
public Task Handle(
Request request,
CancellationToken cancellationToken)
{
Console.WriteLine(
$"[Файл] Письмо с темой '{request.Subject}' отправлено с адреса '{request.EmailFrom}' на адрес '{request.EmailTo}': {request.Body}");
return Task.CompletedTask;
}
}
}
тогда при создании запроса нужно указывать оба класса:
protected async Task MailSentAsync(
string emailFrom,
string emailTo,
string subject,
string body)
{
var request = new MailSent.Request
{
EmailFrom = emailFrom,
EmailTo = emailTo,
Subject = subject,
Body = body
};
await _mediator.Publish(request);
}
При попытке перейти «по щелчку» к классу MailSent нам будет предложен выбор перейти к запросу или к реализации.
Дополнительные возможности
В MediatR есть удобная реализация поведения конвейера (pipeline behavior). Для этого используется интерфейс IPipelineBehavior<TRequest, TResponse>.
Так, можно добавить какую-то обработку для каждого вызова Handle из классов унаследованных от IRequestHandler. Например, логирование, на примере которого мы рассматривали реализацию обработки событий.
К сожалению, мы можем использовать PipelineBehavior только для IRequest и не можем для INotification.
Чтобы реализовать подобную функциональность для событий нужно переопределить NotificationPublisher.
class Program
{
static async Task Main()
{
var serviceCollection = new ServiceCollection()
.AddMediatR(config =>
{
config.RegisterServicesFromAssembly(Assembly.GetExecutingAssembly());
config.NotificationPublisher = new MailSentPublisher();
config.NotificationPublisherType = typeof(MailSentPublisher);
})
.BuildServiceProvider();
var mediator = serviceCollection.GetRequiredService<IMediator>();
EmailService emailService =
new EmailService(mediator: mediator, emailFrom: "hr@disney.com");
await emailService.SendMailToUserAsync(
emailTo: "Milo.Murphy@disney.com",
subject: "Welcome to Disney",
body: "Today is your first day...");
}
}
class MailSentPublisher : INotificationPublisher
{
public async Task Publish(
IEnumerable<NotificationHandlerExecutor> handlerExecutors,
INotification notification,
CancellationToken cancellationToken)
{
foreach (var handler in handlerExecutors)
{
try
{
Console.WriteLine(
$"Перед запуском {handler.HandlerInstance.GetType().Name}");
await handler.HandlerCallback(notification, cancellationToken)
.ConfigureAwait(false);
}
catch (Exception e)
{
Console.WriteLine($"Произошла ошибка {e.Message}");
}
finally
{
Console.WriteLine(
$"После запуска {handler.HandlerInstance.GetType().Name}");
}
}
}
}
Результат:
Перед запуском ConsoleHandler
[Консоль] Письмо с темой 'Welcome to Disney' отправлено с адреса 'hr@disney.com' на адрес 'Milo.Murphy@disney.com': Today is your first day...
После запуска ConsoleHandler
Перед запуском FileHandler
[Файл] Письмо с темой 'Welcome to Disney' отправлено с адреса 'hr@disney.com' на адрес 'Milo.Murphy@disney.com': Today is your first day...
После запуска FileHandler
Так, мы добавили некую обработку до и после запуска каждого обработчика события, а еще обеспечили выполнение следующих, даже если в предыдущем возникла ошибка.
Вместо заключения
Мы рассмотрели несколько вариантов реализации обработчиков Событий: с помощью стандартных средств C#, с помощью средств библиотеки MediatR и написали самостоятельно, реализовав паттерн Наблюдатель. В разных ситуациях может быть удобно использовать разные варианты, но полезно знать и об альтернативных возможностях.
Объект за орбитой Нептуна должен быть весьма массивным.
Когда дело доходит до открытия планет в Солнечной системе, есть два основных метода. Первый заключается в прямом наблюдении. Так издревле были известны Меркурий, Венера, Марс, Юпитер и Сатурн. В 1781 году Уильям Гершель таким образом обнаружил Уран. А вот Нептун из-за большой удалённости от Солнца удалось вычислить лишь математически. В этом заключается второй способ.
Местонахождение Нептуна, как и само его существование, было предсказано по его влиянию на орбиту Урана. Аналогичным методом учёные пытаются воспользоваться и в попытках найти девятую планету, само существование которой остаётся под вопросом, но будоражит умы астрономов и обывателей.
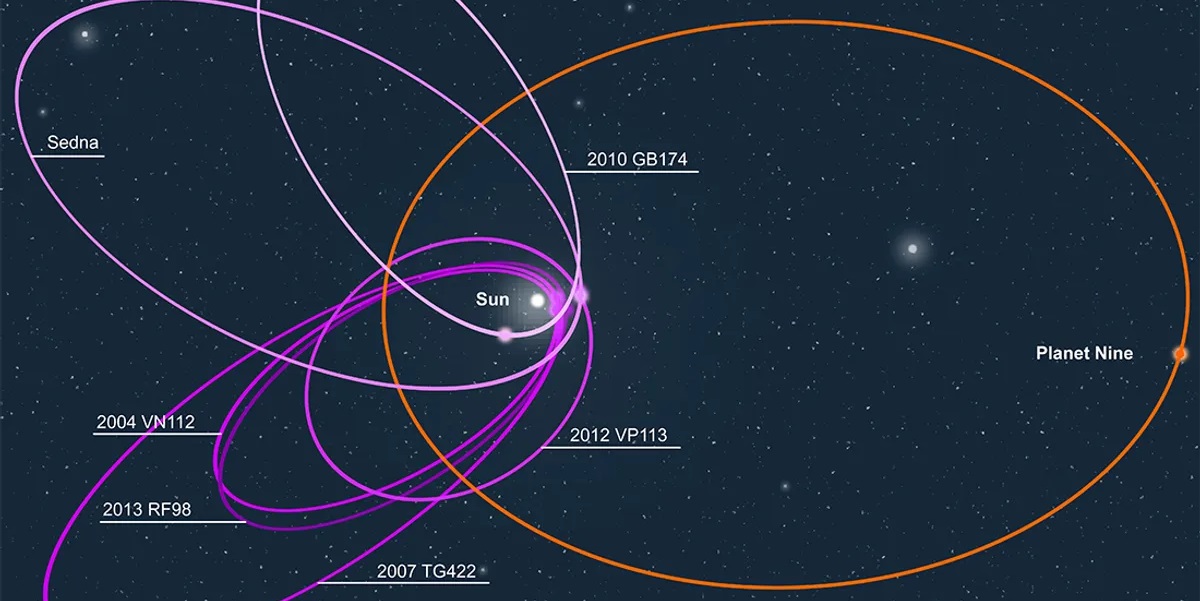
В 2015 году учёные из Калифорнийского технологического института опубликовали исследование, в котором анализировали группировку шести объектов за орбитой Нептуна. Они располагались таким образом, что лишь какое-то тело с большой массой могло объяснить подобное расположение. Впрочем, скептики считали, что этот вывод несостоятелен, потому что может быть результатом статистической ошибки.
Но появилось новое исследование, в котором команда учёных проанализировала долгопериодические орбиты объектов, пересекающих траекторию Нептуна. Было выявлено, что их ближайшие к Солнцу позиции сгруппированы в диапазоне от 15 до 30 астрономических единиц. Собранные данные были занесены в модель, которая должна была описать, при каких условиях могла сложиться такая картина.
Лучшее предсказание даёт модель, которая учитывает массивную планету за пределами орбиты Нептуна. Она хорошо объясняет орбитальную устойчивость исследованных объектов. Причём значительно лучше, чем модель, не включающая девятую планету, и модель, которая пытается учесть галактические приливы и гравитационное влияние других звёзд.
Хотя это исследование и интригует, оно не позволяет точно определить, где именно искать девятую планету. В этом учёные планируют положиться на наблюдательную астрономию, технологии которой продолжают развиваться. Вполне возможно, что какие-то новые обсерватории смогут напрямую запечатлеть девятую планету.
Только изучили один инструмент, как сразу же появились новые? Придется разбираться! В статье мы рассмотрим новый тип баз данных, который отлично подходит для ML задач. Пройдем путь от простого вектора до целой рекомендательной системы, пробежимся по основным фишкам и внутреннему устройству. Поймем, а где вообще использовать этот инструмент и посмотрим на векторные базы данных в деле.
Меня зовут Мозганов Николай и я backend разработчик в Точке. До недавнего времени я разрабатывал социальную сеть для предпринимателей, которая помогает находить полезные бизнес знакомства. Давайте возьмем этот сервис в качестве примера, чтобы плавно погрузиться в проблему, решаемую векторными базами данных.
Кратко про ML и векторизацию
Итак, мы разрабатываем сервис, в котором пользователи заполняют свои интересы, указывают экспертизу и пожелания по встрече, а мы должны подобрать интересного собеседника. На вход мы получаем тексты с информацией о пользователях, а на выходе должны выдать пары рекомендаций. По сути мы делаем умную рекомендательную систему и наша задача сводится к нахождению максимально похожих экспертиз одних клиентов и запросов других клиентов.
Например, Вася хочет пообщаться с опытными предпринимателями, а дизайнер Петя планирует выходить на маркетплейсы и ищет человека с такой экспертизой. Подходят ли они друг другу? Эта задача не так проста, как может показаться на первый взгляд. Давайте вместе попробуем ее решить.
Решение в лоб
Очевидной идеей кажется простое разбиение пользовательских текстов на слова (токены). В качестве рекомендаций будем выдавать тех людей, у которых совпало наибольшее количество слов: общие слова будут звучать в тексте, а значит людям интересны одни и те же темы. Чем больше совпадений, тем лучше! Можно наливать кофе)
Но такая рекомендательная система получится не очень умной, поскольку она не учитывает общий контекст запроса, синонимы и какие-то опечатки.
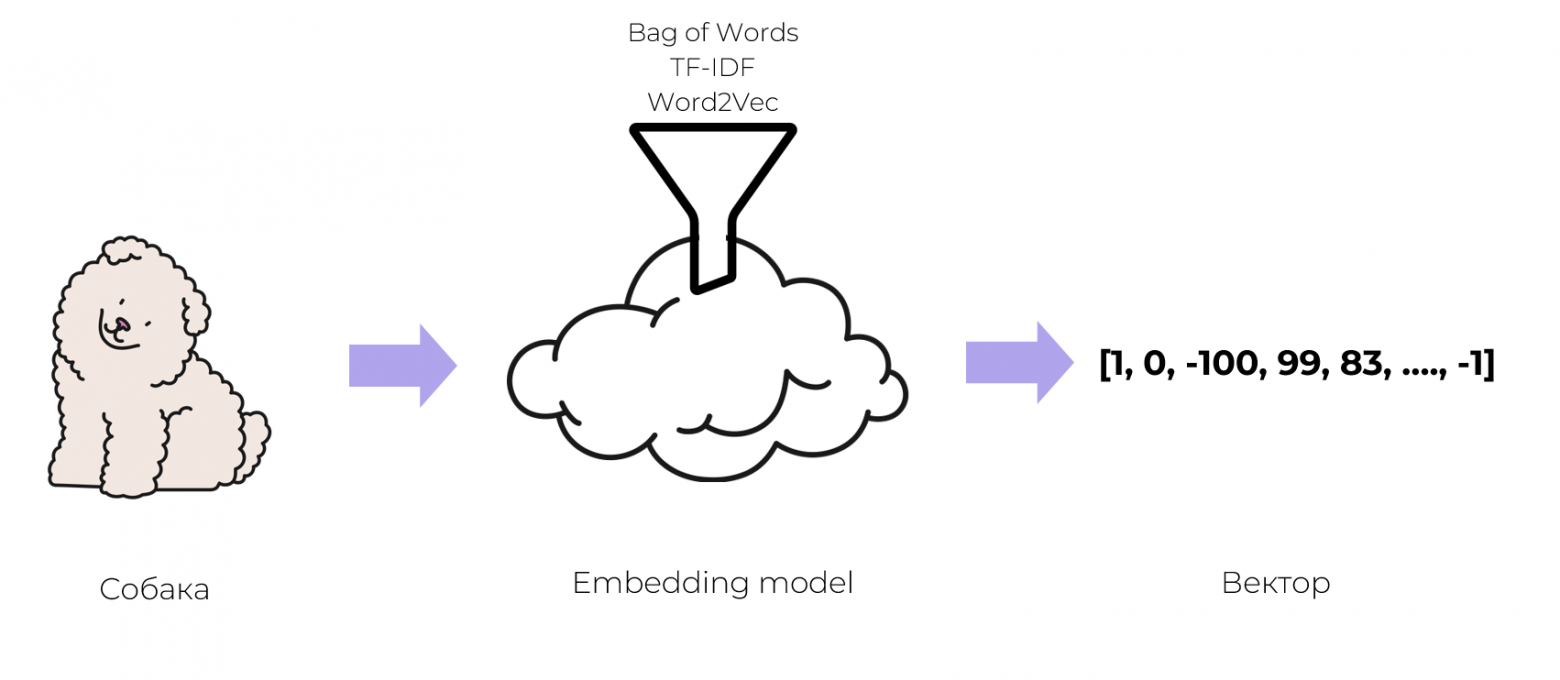
Задачу решать все-таки надо, придется обратиться за помощью к ML’щикам. Они предлагают хранить не обычные тексты, а числовые представления или по простому вектора, чтобы их понимали программы. Оказывается, практически любые объекты можно превращать в вектор: слова, предложения, картинки или даже звуки. Такой процесс называется векторизацией.
Превратить объект в вектор — это задача машинного обучения. Есть разные подходы и уже обученные модели, которые на вход получают объекты, а на выходе дают вектор. Например, Bag of Words, TF-IDF, Word2Vec и другие. Для простоты понимания можно воспринимать этот процесс как некоторую математическую магию.
МЛщики, конечно, могут много всего интересного придумать, но бэкендерам надо разбираться, как это все хранить в памяти, поэтому вспомнить, что такое вектор все-таки придется. Нам же нужно с ними работать!
Назад в школу
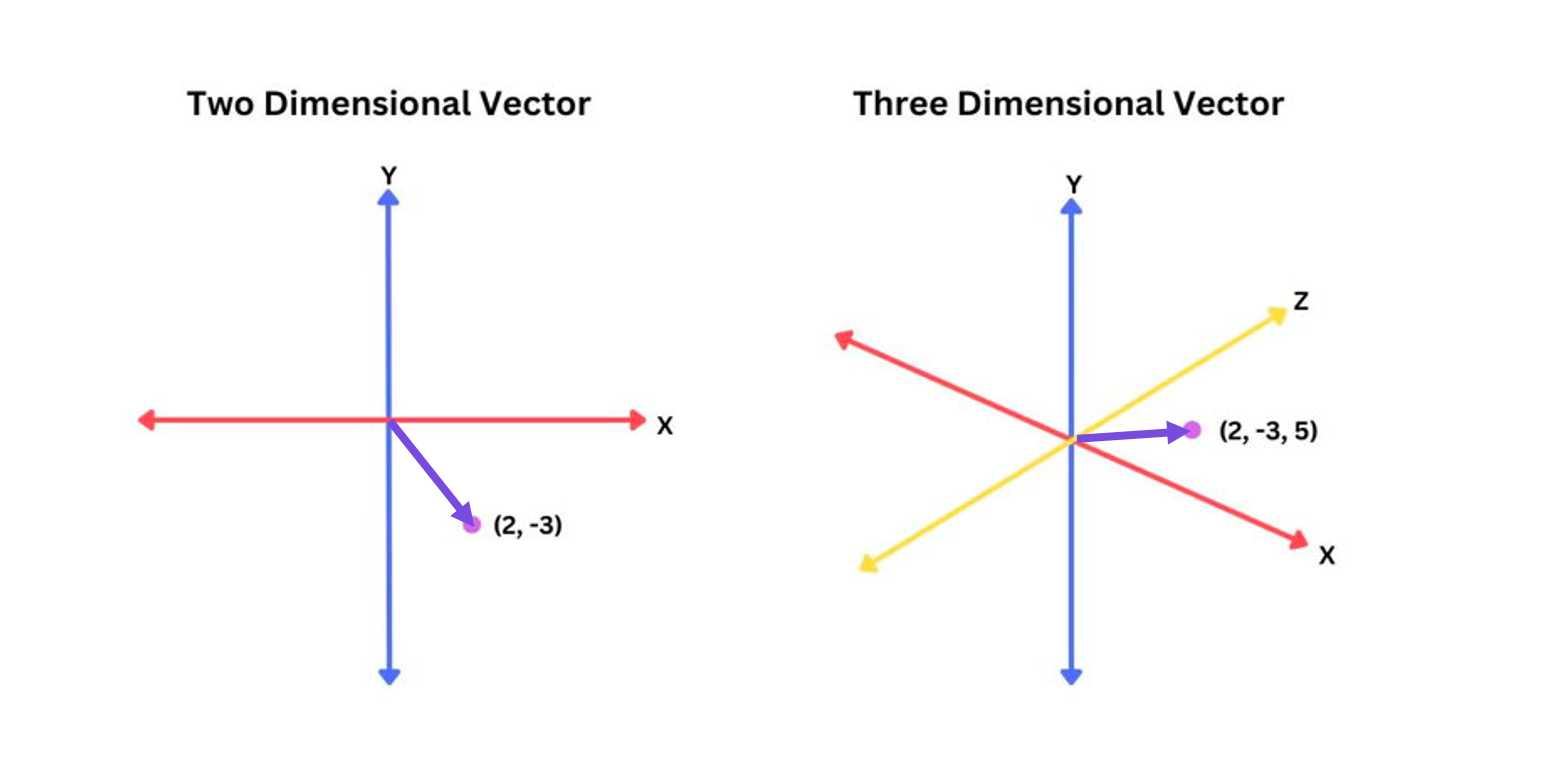
Вектор — это элемент векторного пространства со своими свойствами и операциями.
У каждого вектора есть координаты и бла бла бла. Не очень понятно, как это использовать на практике.
На самом деле вектор — это просто массив чисел, а массивы мы уже умеем обрабатывать и хранить в памяти. Самое главное свойство для нашей задачи заключается в том, что между 2-мя векторами можно искать расстояние. Интуитивно это означает, что примерно похожие друг на друга вектора, находятся на близком расстоянии. По сути математические метрики и формулы описывают наше интуитивное представление.
Примеры метрик:
1) Евклидово расстояние (L2-норма). Расстояние в обычном его понимании.
Формула:
Пример: Есть два вектора
евклидово расстояние между ними:
2) Манхэттенское расстояние (L1-норма)
Формула:
Пример: Для тех же векторов манхэттенское расстояние
3) Косинусное сходство. Технически это не истинная метрика расстояния, а мера сходства.
Формула для косинусного сходства:
Здесь
Для нахождения расстояния используем:
Пример:
Косинусное расстояние будет:
Такое маленькое расстояние указывает на то, что векторы весьма похожи.
Продвинутое решение
На такой математической идее и работает наш сервис: Мы превращаем описание пользователей в различные вектора, между которыми можно искать расстояние, а по полученным расстояниям делаем сортировку и выдаем рекомендации.
def _get_recommended_match_asymmetric(
users_df: pd.DataFrame,
forbidden_ids: list[ForbiddenUserIdPair]
) -> pd.DataFrame:
df, embedding_model = processing.prepare_df_and_vectorizer(users_df)
# считаем score для рекомендаций
match_score = np.zeros([len(df), len(df)])
for column_pair in MATCH_COLUMN_PAIRS: # пары колонок. Например, (запрос пользователя на био пользователя)
match_score += processing.text_dist(df, embedding_model, column_pair)
np.fill_diagonal(match_score, -1) # запрещаем рекомендовать самих себя
ind_to_id = df['user_id'].to_dict()
# Отбираем наиболее подходящих ранее не рекомендованных
recommended_id = [
(ind_to_id[user_ind], ind_to_id[recommended_ind])
for user_ind, recommended_ind in
distributions.get_recommended_from_dist_asymmetric(match_score, forbidden_ids=forbidden_ids)
]
# соберем финальный датафрейм
df_rec = pd.DataFrame(recommended_id)
df_rec.columns = ['user_id', 'rec_id']
df_rec = df_rec.groupby(by='user_id')['rec_id'].apply(', '.join).to_frame()
return df_rec['rec_id'].str.split(', ', expand=True).reset_index()
У этого решения есть принципиальные проблемы:
Во-первых, оно долго работает.
Во-вторых, мы выгружаем всю таблицу с векторами в память нашего приложения, чтобы вычислить расстояния и отсортировать их.
Эти проблемы хочется как-то решить и тут на помощь приходят они…
Векторные базы данных
Оказывается, есть векторные базы данных (ВБД). Это NoSQL решения, которые предназначены для хранения, индексирования и поиска похожих векторов.
Следовательно, с их помощью можно строить:
Различные рекомендательные системы. Например, рекомендовать похожие товары в интернет магазине на основе свойств исходных товаров.
Поисковые системы — искать наиболее похожие разделы по смысловой нагрузке текста.
Делать различный анализ изображений и видео. Например, искать похожие картинки или находить оригинал изображения.
Устройство
По существу, от базы данных требуется две операции: сохранять данные и читать информацию, записанную ранее. Давайте рассмотрим как работают эти процессы в векторных базах:
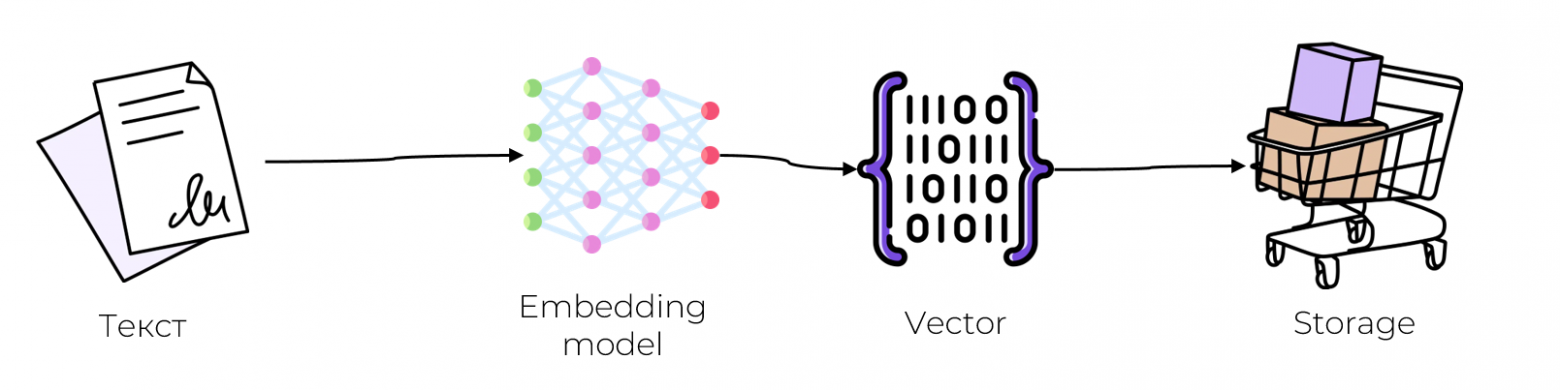
Запись
На вход backend-приложения поступает какой-то объект (пусть это будет текст, как в нашем сервисе)
Этот объект нужно превратить в вектор при помощи обученного векторизатора.
Полученный вектор и метаданные исходного объекта можно сохранить на диск.
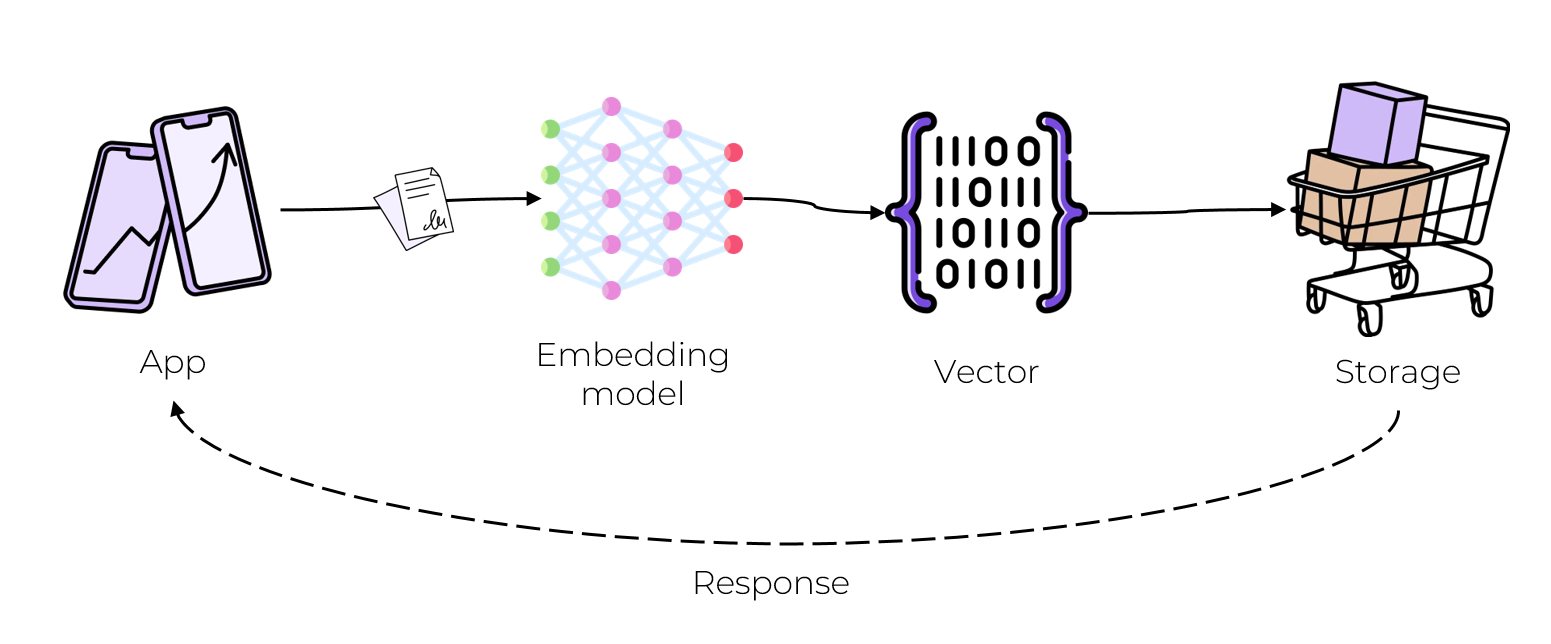
Чтение
К нам приходит приложение с новым объектом и запросом сделать для него рекомендацию.
Нужно проделать весь процесс обработки: векторизовать объект запроса той же моделью, получить вектор той же размерности.
Уже по сгенерированному вектору можно найти другой, наиболее близкий вектор. На этом этапе можно сделать предварительную фильтрацию по метаданным (Например, искать соседей только с длинной текста больше n).
Поиск наиболее подходящих соседей может работать долго, ведь нужно просмотреть все записи на диске. Решением этой проблемы, как и в большинстве баз данных, является индексация. Мы чуть замедлим запись, но чтение будет работать сильно быстрее. Для этого могут использоваться разные алгоритмы индексации, подробнее к которым вернемся дальше.
Функционал одних баз данных заканчиваются только хранением, индексацией и чтением, а другие могут включать в себя готовый набор векторизаторов, чтобы не нужно было писать и обучать свои. Набор возможностей из коробки зависит от конкретной базы данных.
Индексирование
Индексирование уже упоминалось, но не пояснялось, как именно оно работает. ВБД используют комбинацию различных алгоритмов и структур данных, которые участвуют в поиске приближенного ближайшего соседа. Запрос схожих векторов предоставляет приблизительные результаты, поэтому мы можем балансировать между точностью и скоростью: чем точнее хотим получить результат, тем медленнее будет работать запрос и наоборот.
Ускорить поиск можно несколькими способами: либо уменьшить размерность векторов, либо сузить область поиска. Рассмотрим парочку алгоритмов индексирования, попытаемся понять в чем заключается идея и почему поиск становится быстрее.
Уменьшение размерности, при помощи случайной проекции
По длинным векторам искать долго, давайте их «укоротим». Нужно уменьшить размерность векторов, сохранив свойство схожести. Это можно сделать согласно лемме Джонсона-Линденштрауса, которая утверждает, что небольшой набор точек в пространстве большой размерности может быть вложен в пространство гораздо меньшей размерности таким образом, что расстояния между точками почти сохраняются.
Для реализации придется сгенерировать матрицу случайной проекции, на которую будем скалярно умножать входные вектора. На выходе получаем вектора меньшей размерности, которые сохраняют свойство подобия. Мы жертвуем некоторым количеством информации, поэтому точность уменьшается, но скорость увеличивается, т.к. размер векторов становиться сильно меньше.
Размер матрицы можно задавать таким, чтобы конечный результат нас устраивал, т.е. конечный размер векторов был оптимальным для поиска).
В момент запроса похожести для нового вектора, мы должны использовать ту же матрицу, чтобы спроецировать вектор запроса в пространство более низкой размерности. И уже в этом пространстве делать поиск ближайших соседей.
Хэширование с учетом местоположения
Locality-sensitive hashing (LSH) — это метод индексации, который чем-то похож на устройство обычной хэш мапы. Идея заключается в следующем: отобразим вектора в бакеты похожести, используя набор функций хеширования. Проще всего рассмотреть на примере:
Зеленый вектор отображается в зеленый сегмент 1-го бакета, а синий вектор — в синий сегмент 2-го бакета.
Хэш функция определяет, в какой из бакетов попадёт вектор. По своей сути она позволяет нам группировать похожие вектора в одни и те же бакеты.
Соответственно, чтобы найти ближайших соседей для вектора запроса, нужно определить его бакет при помощи функции хэширования. Выполнить поиск можно среди данного бакета, не рассматривая другие, предварительно неблизкие, вектора. Этот метод намного быстрее, чем поиск по всему набору данных, потому что в каждом бакете гораздо меньше векторов, чем во всем пространстве.
Так же стоит упомянуть, что качество данного метода зависит от свойств выбранной функции хэширования точно так же, как и в устройстве обычной хэш мапы.
Иерархический навигационный маленький мир
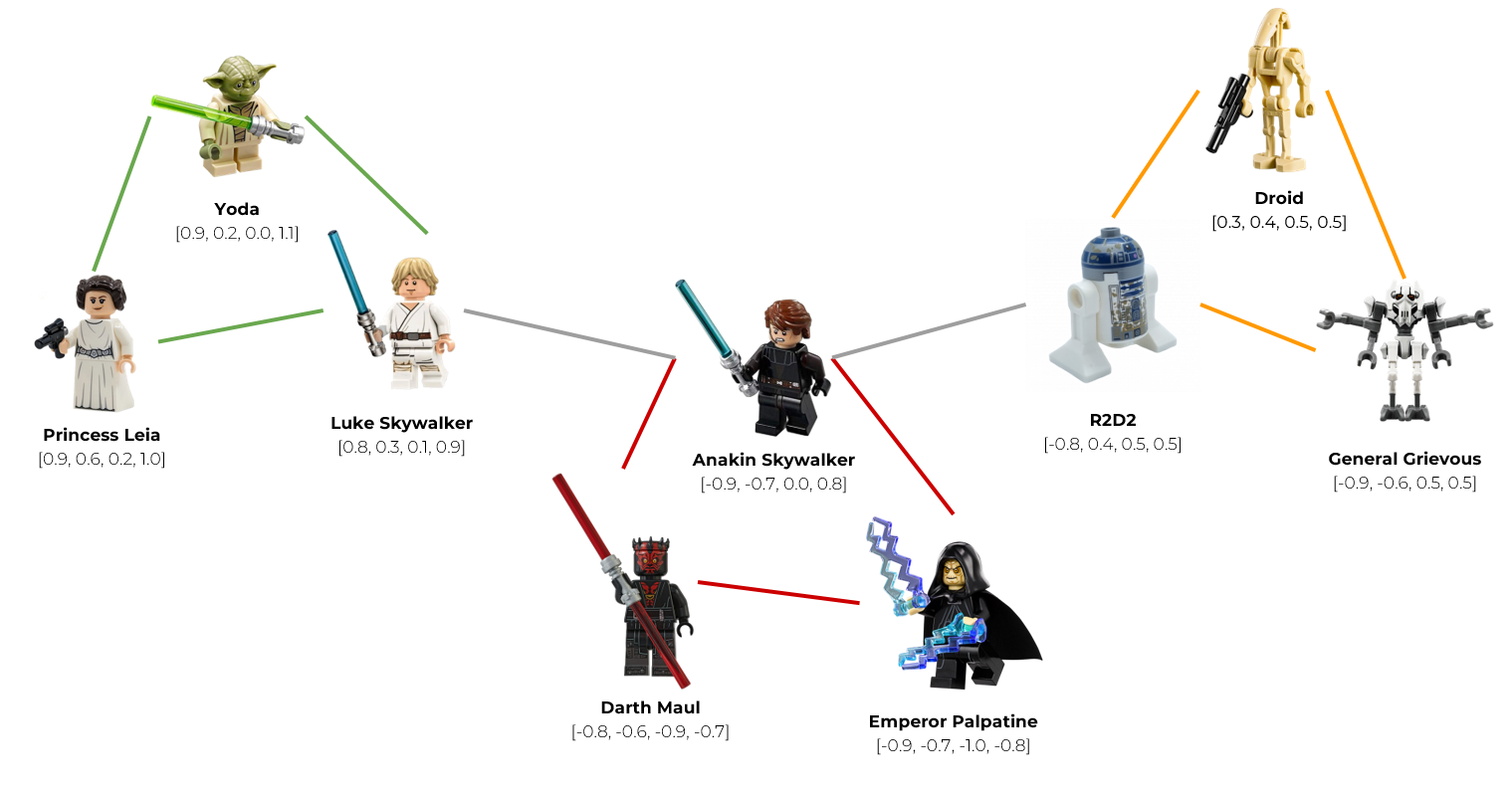
Hierarchical Navigable Small World (HNSW) — на первый взгляд сложный и непонятный алгоритм, который требует построения графа поиска, однако он очень важен и полезен, поскольку используется практически во всех современных ВБД, обеспечивая хорошую точность и скорость.
На самом деле идея довольно просто объясняется при помощи LEGO человечков.
Представим, что наши вектора обозначают персонажей из фильма «Звездные войны».
Сгруппируем вектора в узлы (случайно или с помощью алгоритмов кластеризации). Объединим Йоду, Люка, и принцессу Лейлу в узел светлой стороны (зеленый узел). Героев темной стороны объединим в красный узел, а роботов и клонов — в 3й узел будущего графа. Получилось 3 узла: зеленый, красный и оранжевый.
Проанализируем вектор каждого узла и нарисуем серое ребро между двумя узлами, если они содержат в себе похожие вектора (т.е. расстояние между векторами меньше некоторой заданной константы). Например, Люк Скайуокер очень похож на своего отца Энакина Скайуокера, поэтому эти узлы мы можем связать ребром. Точно так же с роботом R2D2. Его хозяином был Энакин, поэтому они чем-то похожи. Соответственно, эти узлы так же свяжем ребром.
Таким образом, мы построим граф поиска, в котором каждый узел имеет связь с другими наиболее похожими узлами.
Когда к нам приходит запрос, мы можем использовать этот граф для навигации, посещая только те узлы, которые содержат вектора, наиболее близкие к вектору запроса. Например, мы хотим выдать рекомендацию для Люка Скайвокера, но Йоду и Принцессу Лейлу мы ему уже рекомендовали, поэтому они нам не подходят. Мы пройдемся по ребру и найдем новую рекомендацию — его отца, Энакина Скайвокера.
Мы рассмотрели ключевые идеи индексации в векторных базах данных, но далеко не все. На практике устройство намного сложнее, ведь нужно учитывать множество краевых случаев. Однако, цель этой статьи — ознакомить с ключевыми идеями, чтобы появилось примерное понимание работы.
Пробуем на практике
Вернемся к нашей задаче по рекомендации собеседников. Выберем конкретную базу данных и сравним ее с нашим решением, которое основано на подсчете расстояния между векторами.
Для проведения экспериментов, я руководствовался следующими критериями: хотелось взять OpenSource базу данных, которую можно было бы легко развернуть у себя, а наличие встроенных векторизаторов было весомым плюсом, поскольку я занимаюсь бэкендом и не претендую на экспертность в машинном обучении. На практике это означает, что не придется заморачиваться с преобразованием текстов в вектора и совмещением интерфейсов нашего решения и ВБД.
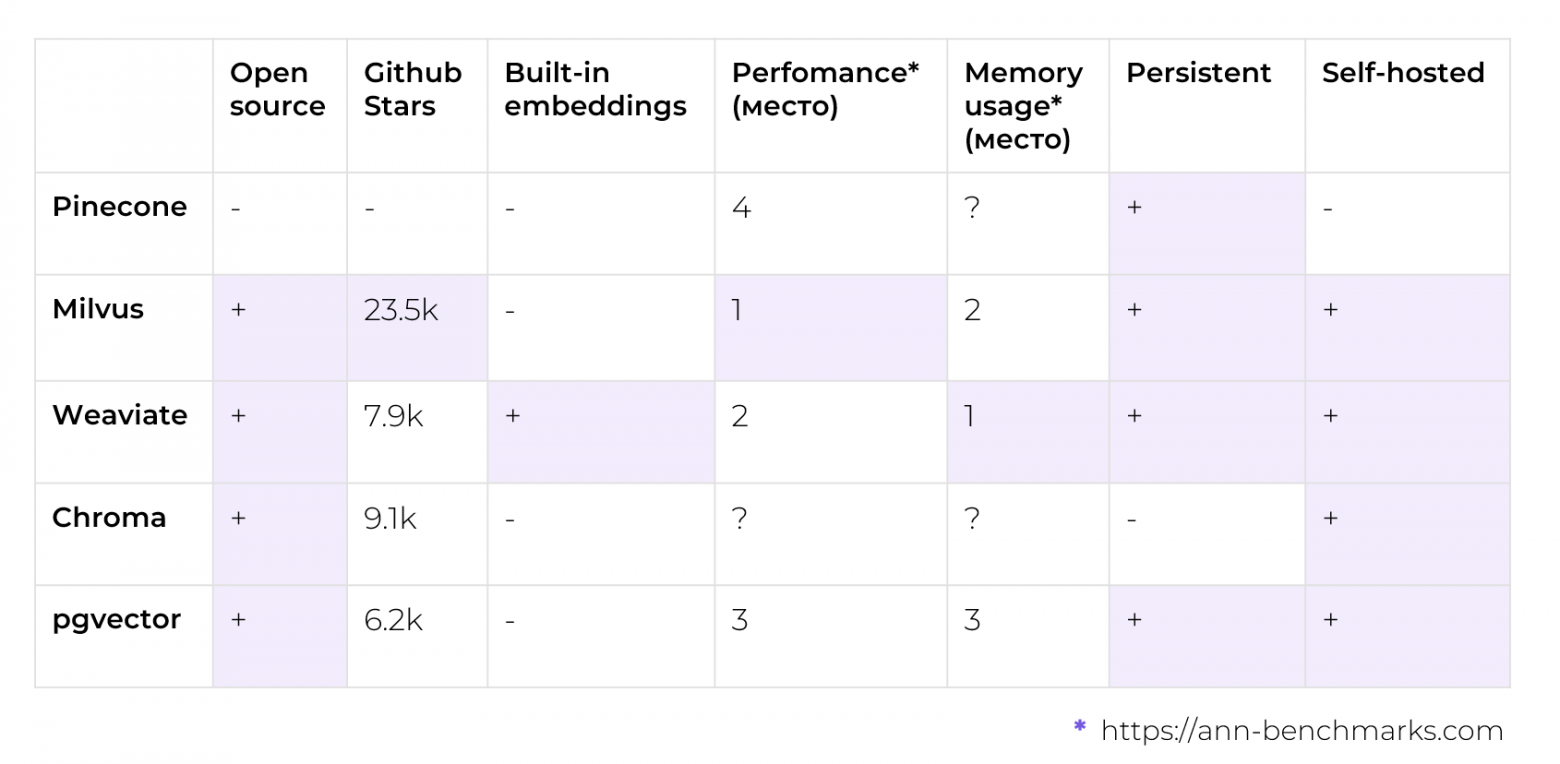
В таблице представлены самые популярные векторные базы данных (или расширения существующих БД, см. pgvector). Ранжирование по производительности и потреблению памяти представлено по местам. Это сделано так, потому что на разных датасетах базы данных ведут себя по-разному: где-то выигрывает одна, где-то другая, поэтому приводить конкретные цифры было бы не совсем честно. Если усреднять, то можно упорядочить их по местам, как представлено в табличке. С подробными результатами бенчмарков можно ознакомиться на https://ann-benchmarks.com/.
Именно для бенчмарка быстрее и проще всего было взять БД с готовым векторизатором, чтобы не писать кучу кода для совместимости. После сортировки по популярности и производительности мой выбор пал на векторную базу данных Weaviate, вдобавок к которой идет неплохая документация.
Бенчмарки
Настало время провести замеры. Оба решения были запущены локально в docker контейнерах, а замеры производились с помощью docker container stats.
На чем проводились замеры
Mac os Ventura 13.5
CPU 2,6 GHz 6‑ядерный процессор Intel Core i7
Memory 16 ГБ 2667 MHz DDR4
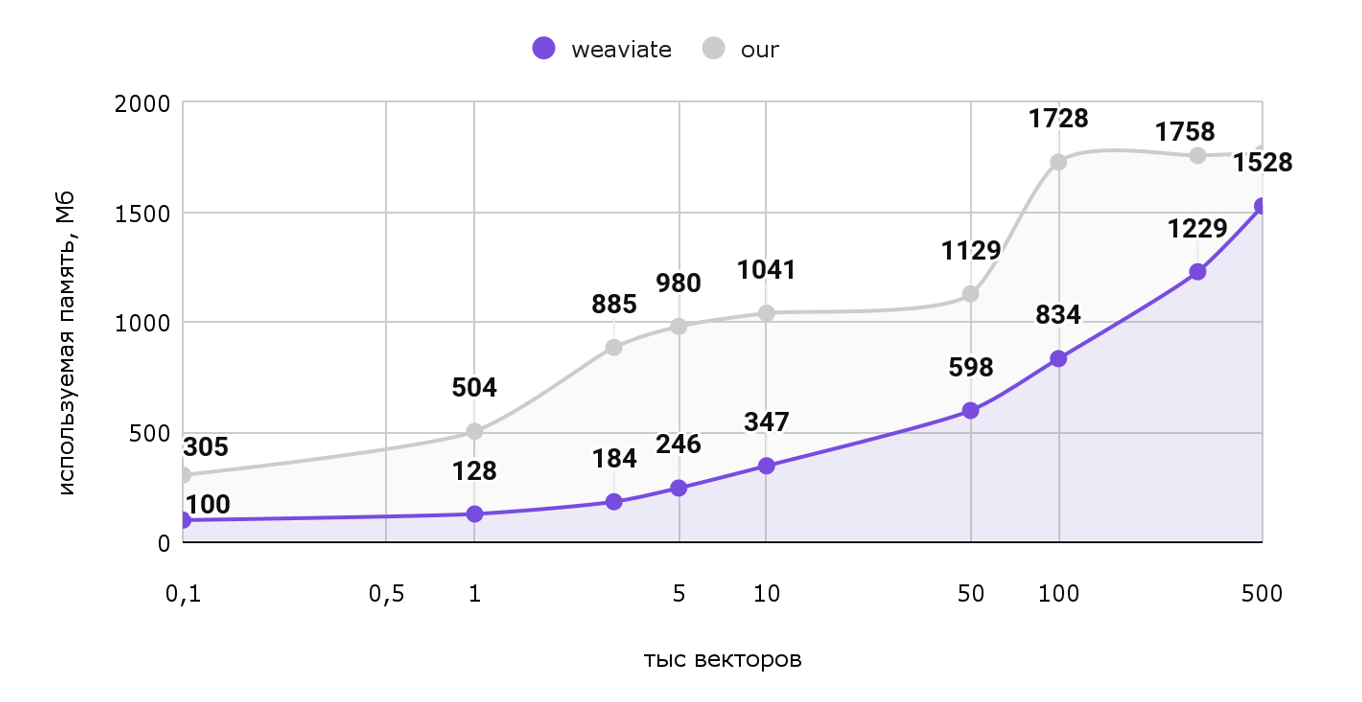
Рассмотрим график используемой памяти от количества векторов. По горизонтальной оси отложены тысячи векторов (т.е. шкала от 100 векторов до полумиллиона), а по вертикальной оси — используемая память в МБ.
Как мы видим наше решение занимает больше памяти во всех тестах, хотя разница незначительна. Ради такого результата не стоило бы и переезжать.
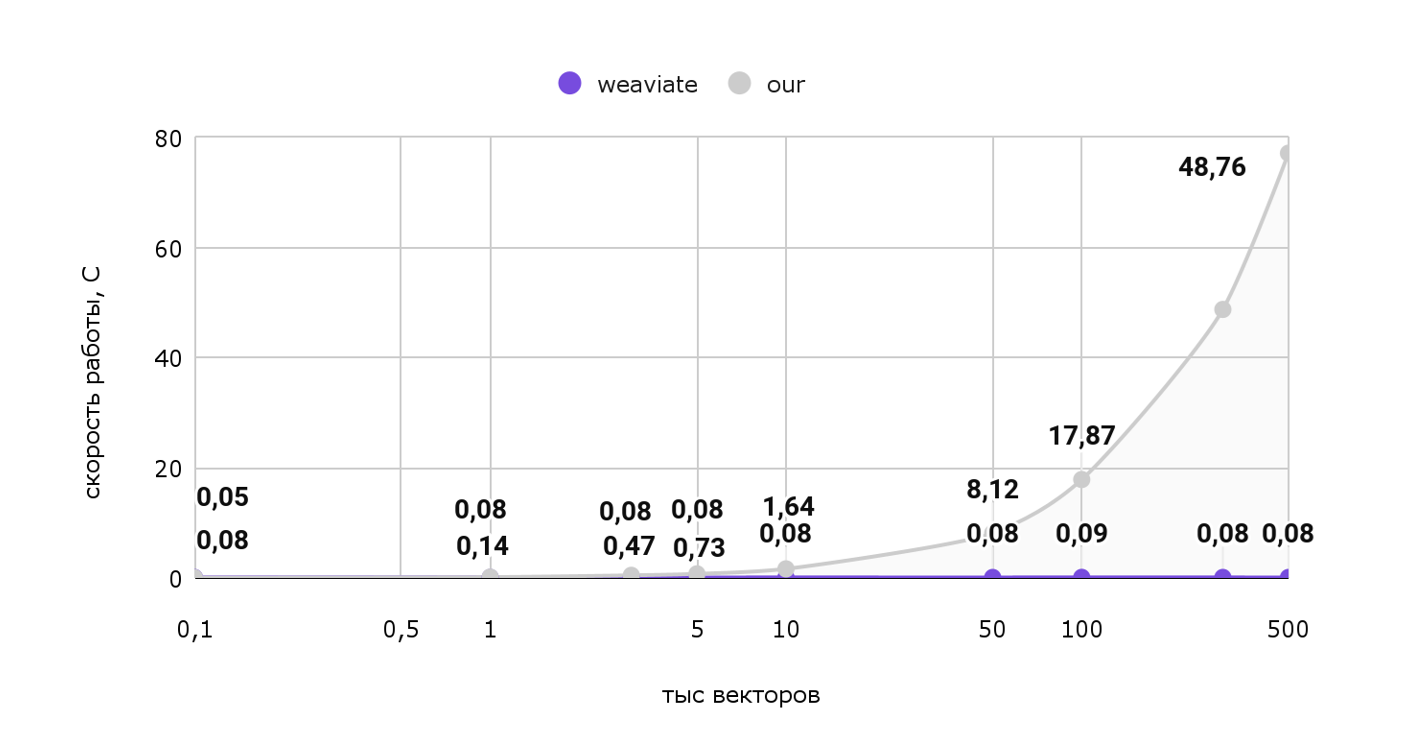
Память — это хорошо, но больше интересует скорость работы. Попробуем выдать 1 рекомендацию для нашего пользователя и посмотрим на затраченное время:
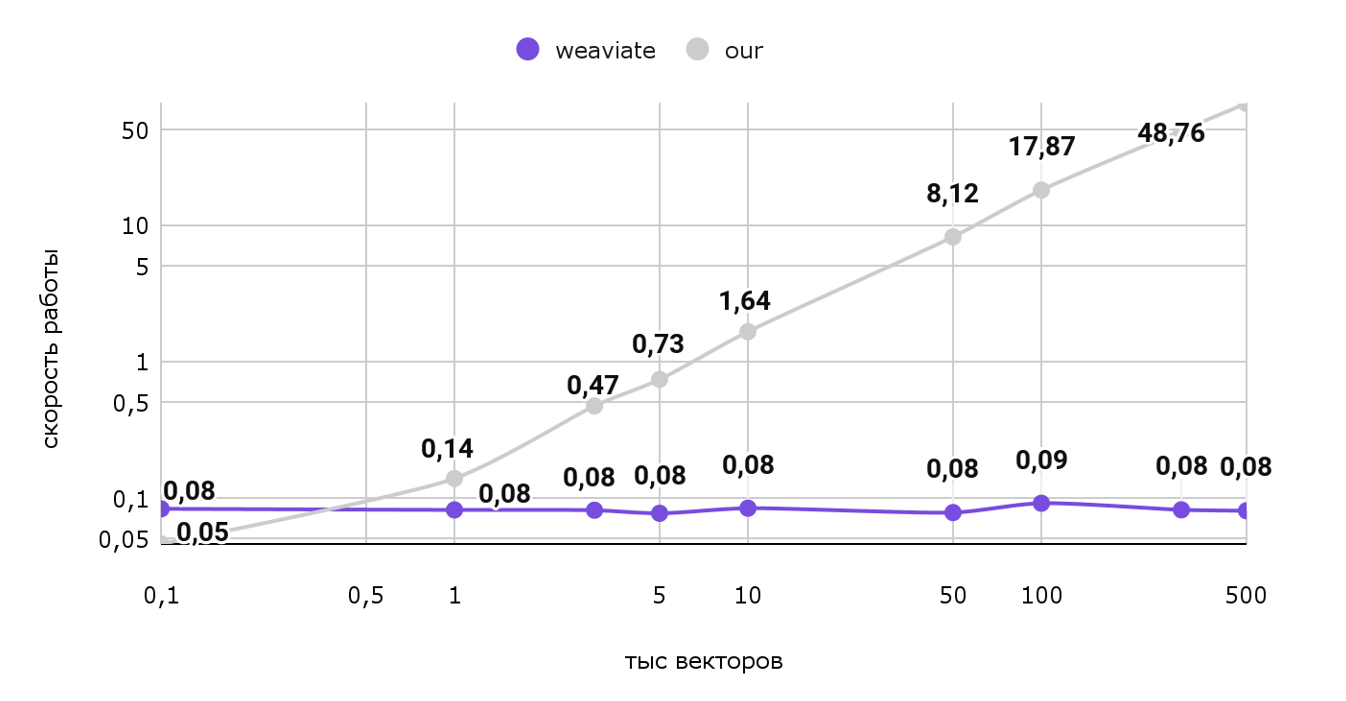
Тут картина уже сильно меняется. Откровенно говоря, наше решение работает непростительно долго на больших объемах: Для выдачи всего 1 рекомендации тратится 77 секунд. И как видно из графика при росте объемов эта цифра будет только расти, а вот векторная база данных работает практически за константное время, с учетом погрешности. Чтобы лучше заметить разницу, посмотрим на эти же данные на логарифмической шкале:
Таким образом, использование векторной базы данных в нашем случае сильно ускорит выдачу одной рекомендации для пользователя. Т.е. рекомендации можно будет делать даже в режиме реального времени! Вдобавок, сэкономим пару мегабайт памяти.
У использования готовых инструментов есть еще одно большое преимущество: алгоритмы и структуры данных уже написаны за нас, поэтому нам не нужно реализовывать их повторно, исправлять баги и поддерживать собственное решение.
Всего-то достаточно развернуть векторную базу данных и сделать пару служебных запросов. Благодаря этому количество кода нашего приложения сильно снижается, освобождается время на кофе)
Итоги
Векторные базы данных предназначены для оптимальной работы с векторами. Они по-умному хранят и индексируют эту структуру данных, соответственно делают быстрый поиск по ней. Самая главная фишка — нахождение похожих векторов.
А еще некоторые базы данных поставляют готовый модуль векторизации, поэтому не нужно глубоко погружаться в машинное обучение, чтобы использовать этот инструмент в своих небольших проектах.
Важно понимать, что это не серебряная пуля. У каждого решения есть свои плюсы и минусы, точно так же и с векторными базами данных.
Это NoSQL решение, поэтому нет строгой транзакционности (не выполняются требования ACID). С другой стороны, такой вид БД хорошо горизонтально масштабируется, но сделать это правильно не так просто, из чего вытекают следующие пункты:
Нужно разбираться с индексированием, шардированием (партиционированием) и другими неочевидными вещами.
Нужно поддерживать всю необходимую инфраструктуру, следить за ее работоспособностью.
Изучать новый инструмент и погружать в него всю команду. Это может быть весомым минусом, особенно если сроки ограничены.
Не все работает из коробки: Например, для нашей задачи ВБД не умеют каждый раз выдавать новые рекомендации, хотя это и можно реализовать при помощи аналога курсоров. В общем, все равно придется делать доработки.
В заключение, хотелось бы сказать, что векторные базы данных — интересный инструмент для своих проектов, который однозначно стоит попробовать. Его использование позволяет сильно сократить время на разработку, ведь не нужно заниматься написанием собственного решения, его поддержкой и исправлением ошибок. ВБД ускоряют время поиска и чуть более оптимально используют память. С другой стороны, это не волшебное решение всех проблем: нужно поддерживать необходимую инфраструктуру, обновлять и мониторить ее, поэтому выбор всегда остается за вами. Выбирайте с умом!
Бумажные книги лучше электронных. Комиксы — это не литература. Читать нужно, как минимум, 50 книг в год. А люди, которые не любят читать, неинтересные собеседники. В новом выпуске подкаста обсуждаем распространнённые стереотипы о книгах, которые мешают нам наслаждаться чтением.
— Пытаемся понять, что значит «читающий» человек и действительно ли зазорно не любить читать книги. У нас есть тысяча и один аргумент, почему интеллектуальные способности человека не связаны с его любовью к чтению.
— Вспоминаем недавние обсуждения в интернете о том, можно ли делать в книгах пометки ручкой и маркерами. Лера встаёт на сторону тех, кто «портит» книги.
— Делимся нашим списком «постыдной» литературы. Вика рассказывает, почему стеснялась своего увлечения романами Сесилии Ахерн. Таня пытается вспомнить названия фэнтези из детства, а Лера делится российскими аналогами «Сумерек».
Назревает новый тренд, который наверняка подхватят и другие компании.
Apple заказала у тайваньского поставщика большое количество компонентов ёмкостных кнопок, которые, предположительно, будут использоваться в будущей серии iPhone 16. Об этом со ссылкой на новый отчёт из Азии пишет портал MacRumors.
По данным источника, издания Economic Daily News, заказ Apple получила компания Advanced Semiconductor Engineering. Она будет производить модули SIP, которые будут использоваться для интеграции ёмкостных компонентов с двумя вибромоторчиками Taptic Engine.
Изображение: Appleinsider
В отчёте утверждается, что Apple заменит существующие физические кнопки на обеих сторонах смартфона ёмкостными элементами, которые обеспечат пользователям iPhone 16 тактильную обратную связь. Такие кнопки смогут считывать давление и имитировать нажатие с помощью вибрации.
Apple вполне могла заказать эти кнопки в рамках подготовки к будущим производственным планам, но это не означает, что они предназначены для использования в моделях iPhone 16 этого года.
К тому же, в отчёте утверждается, что ёмкостные компоненты начнут производить в третьем квартале, что необычно поздно с точки зрения типичного графика Apple. Поэтому заказ вполне может быть и на линейку iPhone 17.
Привет, меня зовут Сергей, я ведущий разработчик в DDoS-Guard и человек из мемов xkcd, который любит всё экстраполировать, истовый фанат визуализации данных. Диаграммы и графики решают кучу моих проблем с онбордингом джунов и объяснением задачи исполнителям.
В этой статье я расскажу о нескольких не самых стандартных, но очень полезных диаграммах, и покажу на трех примерах, как визуализация данных помогала мне в моей работе.
Зачем использовать визуализацию
Тема диаграмм всерьез зацепила меня еще в колледже. Я купил книгу от ИНТУИТ (UML: Первое знакомство, Бабич. А.В.), прочел ее и, как говорится, все заверте…
Я создаю диаграммы разными способами. Иногда рисую на доске, попутно объясняя устно, или же пишу код, который сам отрисовывает схемы. Способ не так важен, важен сам формат. Диаграммы можно использовать в GitLab, wiki-статьях и других системах.
Визуализация процессов в большинстве случаев доносит информацию более эффективно, чем текст или аудио. В отличие от этих подходов, где возможны разночтения, визуальную презентацию все понимают примерно одинаково, и это очень удобно.
Основные тезисы этой статьи
Показать — всегда лучше, чем рассказать
Слова + визуал — эффективнее, чем просто слова
Для каждого типа задачи можно придумать свой визуал
Чем лично вам поможет в работе широкое внедрение визуальных диаграмм:
Улучшится практика ведения документации
Будет проще понять друг друга на удаленке при постановке задач
Станут очевидны плюсы подхода Contract First
Дальше я поясню, когда и для каких задач лучше создавать диаграммы, а также постараюсь замотивировать вас искать способы визуализации для себя.
О UML и компании
Unified Modelling Language (UML) был разработан Rational Software и принят в качестве стандарта Object Management Group (OMG) в 1997 году. Периодически объявляют о его смерти и ненужности, но по-моему, для работы UML прекрасно подходит.
Есть и несколько других событийно-процессных нотаций моделирования — например, BPMN (Business Process Model and Notation) и EPC (Event-Process Chain). Различные диаграммы подходят для описания различных типов процессов и дают разные перспективы обзора на них.
Диаграммы могут использоваться на разных этапах жизненного цикла разработки ПО — да и любого производственного процесса в принципе. По сути это просто набор лучших инженерных практик для визуального схематического моделирования сложных систем и этапов сложных процессов.
Diagram as code
Моделирование диаграмм с помощью простого кода, как в той же plantUML — максимально удобно, если вы собираетесь в дальнейшем вносить в них изменения. Можно просто переписать или добавить нужную строчку — и визуальная диаграмма отрисуется заново уже нужным образом.
Для начала можно попросить ChatGPT сгенерировать схему из текстового описания процесса: «Опиши в виде PlantUml что происходит когда …»
К примерам, которые я дам ниже, я приложу их код, чтобы показать, как это просто и эффективно.
Общие советы
Несколько советов общего характера, которые пригодятся при использовании любых диаграмм:
Диаграмма должна быть простой, насколько это возможно.
Лучше разбить процесс на несколько простых диаграмм, чем запихнуть все в одну сложную.
Чем больше вы рисуете и обсуждаете диаграммы, тем больше прокачиваетесь.
Рисовать от руки (хотя бы первую версию) гораздо эффективнее, чем на компьютере, из-за изменения физического способа выражения.
Не придумывайте свои типы диаграмм. Все, что может вам понадобиться, уже существует.
И еще раз: всегда лучше показать, чем описать словесно. Не бойтесь экспериментировать: возможно то, что сейчас кажется сложным, в будущем упростит вам жизнь.
Теперь разберем несколько типов диаграмм, сопроводив их примерами из реального рабочего процесса. В качестве такого процесса я выбрал ситуацию, когда мы создавали визард для заказа услуги защиты от DDoS-атак на сайте.
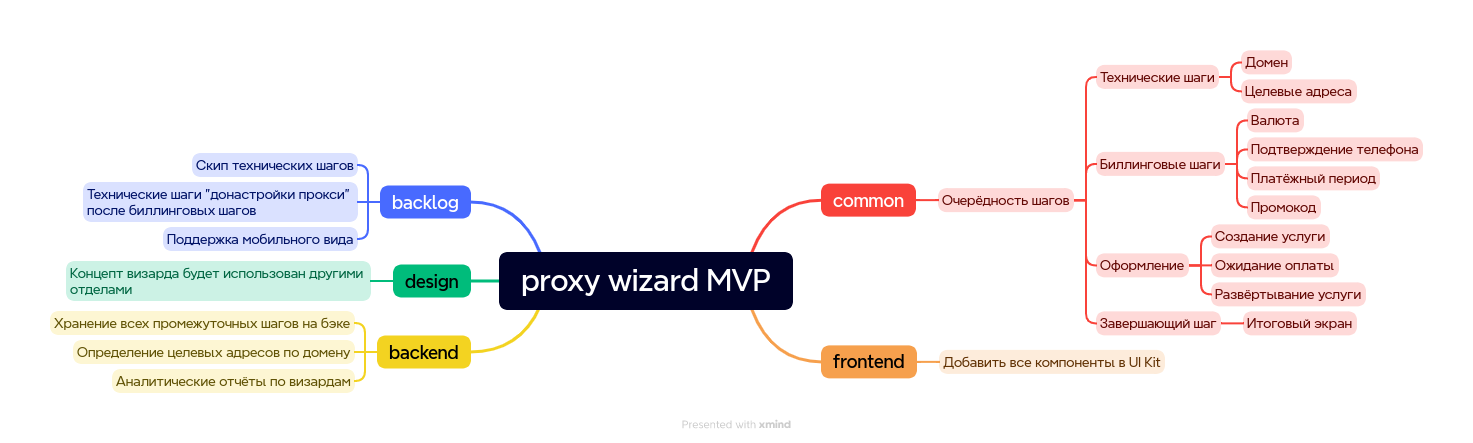
Диаграмма связей (mindmap)
Этот тип диаграмм — расширенный вариант “to do” списка.
Рисуется схема просто: задачу, которая кажется большой и необъятной, разбиваете на крупные подэтапы, а потом стараетесь проанализировать каждый следующий, разбивая его вплоть до простейших действий. Довольно часто по ветвям схемы можно двигаться асинхронно.
Вот как выглядела диаграмма после брифа в самом начале работы над визардом, когда обсудили основные моменты и требования:
Из-за ситуативности эта диаграмма создавалась в приложении xMind, а не plantUml, так как в последнем быстро запечатлеть схему во время брейншторма довольно трудно. Поэтому код не даю.
Рекомендую
Хранить майндмэп в двух форматах: изображение и в формате редактируемого файла, чтобы вносить изменения.
Придерживаться строгих правил нейминга элементов, иначе читать и править будет сложно.
Использовать иконки для эмуляции статусов, если недоступны чекбоксы.
Майндмэп, кстати, хорошо помогает и с практическими бытовыми делами, например, проведением ремонта.
Диаграмма состояния (state)
Этот тип диаграммы используется, чтобы описать поведение систем. Диаграммы состояний отображают разрешенные состояния (статусы) и переходы, а также события, которые на них влияют.
У state-диаграммы высокое КПД, так как схема читабельна даже при 15-20 статусах на ней. Она обладает практически универсальной применимостью — можно использовать для визуализации жизненного цикла услуги, движения судебных дел и любых других процессов.
так мы набросали план устройства нашего визарда для заказа услуги защиты от DDoS на сайте
@startuml
state created as "created"
state setLocations as "set-locations"
state setDomain as "set-domain"
state setTargets as "set-targets"
state setBillingParams as "set-billing-params"
state setPayment as "set-payment"
state createOrder as "create-order"
state settingUp as "setting-up"
[*] -> created: создание визарда
created -> setDomain: ввод и валидация домена
setDomain --> setTargets: ввод и валидация таргетов
setTargets --> setLocations: платная услуга. выбор nлокации размещения защищённых IP
setTargets --> settingUp: FREE
setTargets --> setBillingParams: BASIC
setLocations --> setBillingParams: выбор валюты, биллингового цикла и юр. лица
setBillingParams --> setPayment: физ. лицо. выбор платёжной системы
setBillingParams --> createOrder: юр. лицо с договором
setPayment --> createOrder: клиент соглашается с политиками
createOrder -> pay: клиент оплатил инвойс
createOrder: Создаётся заказ, инвойс и услуга
pay -> settingUp: услуга создана на стороне ddg
settingUp -> success: клиент ознакомился с инструкцией и завершил визард
success -> [*]
@enduml
Рекомендую
Использовать разные цвета для разных состояний
Делать акцент на причины перехода между статусами
Творчески адаптировать расположение блоков под конкретную схему
Диаграмма последовательности (sequence)
Здесь взаимодействие объектов в рамках конкретной ситуации моделируется на основе временной последовательности.
Чаще всего этот тип диаграммы применяется для описания взаимодействия сервисов или отделов внутри компании. Но вообще таким образом можно расписать и процесс найма, и процесс создания контента.
клиент взаимодействует с визардом, процесс от входа до выхода
@startuml
title Покупка Enterprise (новый пользователь, физ. лицо,n оплата рублями, неподтверждённый номер, промокод)
autonumber "<b>[00]"
hide footbox
actor Client
Client -> Frontend: Открывается дашборд
Frontend -> Backend: GET /l7/proxy-wizard/list
Frontend <-- Backend: [{"id":100, "updatedAt":0, "lastStep":"set-created", "type":"proxy"}]
Frontend <- Frontend: Автоматически открывается n последний изменённый визард
Frontend -> Backend: GET /l7/proxy-wizard/detail?id=100
Frontend <-- Backend: {..."type":"proxy", "lastStep":"set-created","filledInput":...}
Client <- Frontend: Отрендерить первый шаг визарда
== Домен ==
Client -> Frontend: Заполнил поле домен "test.com"
Client -> Frontend: Нажал на кнопку "Сохранить"
Frontend -> Backend: POST /l7/proxy-wizard/set-domain?id=100 n{"domain":"ya.ru"}
Frontend <-- Backend: 200
== Таргеты ==
Frontend -> Backend: GET /l7/proxy-wizard/get-targets?id=100
Frontend <-- Backend: [{"ip":"1.1.1.1", "vendor":{"name":"xxx"}}]
Client <- Frontend: Развернуть подшаг с таргетами.nРендер списка таргетов nи их параметров
Client -> Frontend: Добавил таргет "2.2.2.2"
Client -> Frontend: Нажал на кнопку "Сохранить"
Frontend -> Backend: POST /l7/proxy-wizard/set-targets?id=100n {"targets":["1.1.1.1","2.2.2.2"]}
Frontend <-- Backend: 200
== ... Несколько шагов в середине ==
Client <- Frontend: Рендер шага с ожиданием настройки
loop каждые 30 секунд (пока lastStep != setting-up или success)
Frontend -> Backend: GET /l7/proxy-wizard/detail?id=100
Frontend <-- Backend: {"lastStep":"pay"}
end
Backend -> Backend: Активация ордера, настройка услуги
Frontend -> Backend: GET /l7/proxy-wizard/detail?id=100
Frontend <-- Backend: {"lastStep":"setting-up"}
== Success ==
Frontend -> Backend: GET /l7/proxy-wizard/get-success-info?id=100
Frontend <-- Backend: {"content": "<div>content</div>"}
Client <- Frontend: Рендер шага с информацией о настройке услуги
Client -> Frontend: Кликает на ссылку "Перейти к управлению услугой"
Frontend -> Backend: POST /l7/proxy-wizard/done?id=100
Frontend <-- Backend: 200
Client <- Frontend: Редирект на управление услугой
@enduml
Задаем название, прописываем акторов, между которыми будут происходить процессы, и разбираемся со стрелками: одиночная означает первичное действие, двойная — действие в ответ на что-то.
Плюсы sequence-диаграммы: быстро создается и в цифре, и на доске, визуально ее можно разбивать на блоки, можно показывать асинхронные действия и визуально найти все точки отказа.
Рекомендую
Не делать диаграмму слишком широкой, не более 10 действующих лиц
Использовать комментарии, но не описывать условия
Применять нумерацию
Рассказывать историю, а не алгоритм
Диаграммы, которые подходят всем
Диаграмма
Сложность построения
Сложность чтения
Приложения для создания
Диаграмма связей (mindmap)
легкая
легкая
xMind, PlantUML, большая доска
Диаграмма состояния (state)
средняя
легкая
PlantUML, draw.io, доска
Диаграмма последовательности (sequence)
средняя
средняя
PlantUML, draw.io, доска
Вместо заключения
Когда вас спросят: «Чем отличается статус Inactive от Expired в новом функционале?», — отвечайте: «Давай визуализируем это!».
Когда джун у вас поинтересуется: «Какую стратегию мне тут применить?», — отвечайте: «Давай визуализируем это!».
Когда вы приступаете к новой задаче и всё ваше нутро говорит: «Ну сейчас начну писать код, а там разберёмся», то прервите его и вслух скажите — «Давай визуализируем это!».
Кстати, на всех собеседованиях я интересуюсь у кандидатов, как же они визуализируют процессы в своих задачах. И я так и не смог найти своего единственного, кто правильно ответит на этот вопрос. Возможно, это будете вы!
Если интересны такие заметки, в следующий раз расскажу про более экзотические виды диаграмм. А если у вас есть свои зарекомендовавшие себя в работе способы визуализации, кидайте их в комментарии — обсудим.
Как из шутки получился бот, который взял на себя операционную деятельность проджект-менеджера. Рассказывает Егор Попов, PMO из YuSMP Group.
Егор Попов
PMO из YuSMP Group
Когда я стал вливаться в PMO, столкнулся с большим количеством дополнительной операционки, которая съедала много времени. Часть рабочего дня уходила на бесконечные проверки: актуальности плана на день, трудозатрат от разработчиков, состояния документов, дедлайнов на соблюдение и так далее.
Я стал искать способ автоматизировать свои операционные задачи и вспомнил про бота, которого создал шутки ради. Тогда среди менеджеров шутили «Может ли чат-бот заменить ПМа». Самой первой итерацией хотел завести бота, который раз в час просто пишет в группу «Коллеги, есть новости по задачам?». Но пока реализовывал шутку, научил бота делать нечто большее.
Как работает бот
В YuSMP Group у нас есть таблица в Google Sheets, где разбиты планы на разработчиков по дням с указанием приоритетов и заметок. Так как у нас распределенная команда — у одного разработчика могут быть задачи одновременно по нескольким проектам. Чтобы у каждого менеджера было понимание по общей загрузке — используем файлик.
Утром актуализируем план и отправляем его коллегам-разработчикам, чтобы они были в курсе. Бот собирает информацию, анализирует загрузку каждого разработчика и отправляет отчеты в чат для ПМов, указывая, у каких разработчиков (и отделов) план не заполнен.
Бот собирает информацию и анализирует загрузку каждого разработчика. Затем совершает два действия:
Пишет отчет в чатик для PMов о состоянии загрузки, напоминает.
Если всё заполнено — отправляет коллегам-разработчикам план.
Пример сообщения для PM
Пример сообщения для разработчиков
Дальше, я как проджект-менеджер должен держать руку на пульсе. Важно следить за тем, чтобы соблюдались все обязательства перед клиентом. Чтобы не скатываться в микроменеджмент — слежу верхнеуровнево за достижением майлстоунов или дедлайнов.
Списочек таких дедлайнов — ведем так же в таблице.
Бот следит за дедлайнами проектов, проверяя информацию в таблице, и уведомляет PMов:
о дедлайнах на сегодня;
о просроченных дедлайнах.
На оба эти момента обращаю внимание при планировании.
Как бот помог бухгалтерии
У нас возникла проблема с закрытием актов по выполненным работам. PM не имеют доступа к актам (ЭДО), а бухгалтерия не в курсе контекста по проектам. Для решения этой проблемы бот проверяет раз в неделю дельту по платежам в паспортах и отправляет информацию в чатик.
После этого PM оценивают актуальность этих цифр и отмечают реакцией на сообщение. Если что-то не соответствует действительности, они приступают к разрешению проблемы, общаясь в том же чате со всеми заинтересованными сторонами.
В плане ещё интегрировать Jira API с этим ботом (что почти готово), чтобы считать трудозатраты разработчиков по следующим правилам:
За предыдущий день (если рабочий — должно быть от 7 до 9 часов).
За предыдущую неделю по понедельникам (каждый день должен быть заполнен, от 7 до 9 часов).
И возвращать следующую информацию:
Чем вчера занимался разработчик (на каких проектах сколько часов потратил).
Если время заполнено некорректно — тегнуть этого разработчика, напомнить о важности отмечать вовремя трудозатраты.
Если у всех всё окей — передать бухгалтерии информацию (а в будущем автоматически обновлять паспорта проектов).
Из особенностей
Я не написал ни строчки кода, только очень много промтов в чат GPT.
Не нужен хостинг, всё работает автономно в Google Sheets.
Это не стоило ни рубля (кроме генерации картинки в DALLe).
Все куски независимы друг от друга как микросервисы, но при необходимости можно брать данные с соседних таблиц, модифицировать как угоднорасширять.
Из минусов — время исполнения скрипта может достигать 6–8 минут, но это все равно круто оптимизирует работу прожекта.
Прожекты все еще нужны?
Чат-боты никогда не опаздывают на совещания и всегда готовы отчитаться о проделанной работе, и наверняка заслуживают повышения. Но все еще они не могут заменить PM-ов.
Боты могут быть полезными инструментами для автоматизации рутинных задач и упрощения коммуникации. Но нельзя забывать, что за цифровым фасадом все же стоят люди, способные принимать стратегические решения, анализировать данные и решать проблемы. А чат-боты могут остаться теми же хорошими помощниками, которые помогут нам не забыть о важных сроках и задачах.